Poster
in
Workshop: Multimodal Representation Learning (MRL): Perks and Pitfalls
Dynamic Pretraining of Vision-Language Models
AJ Piergiovanni · Weicheng Kuo · Wei Li · Anelia Angelova
Keywords: [ curriculum learning ] [ vision language ] [ sampling ] [ pretraining ]
{kind=link}
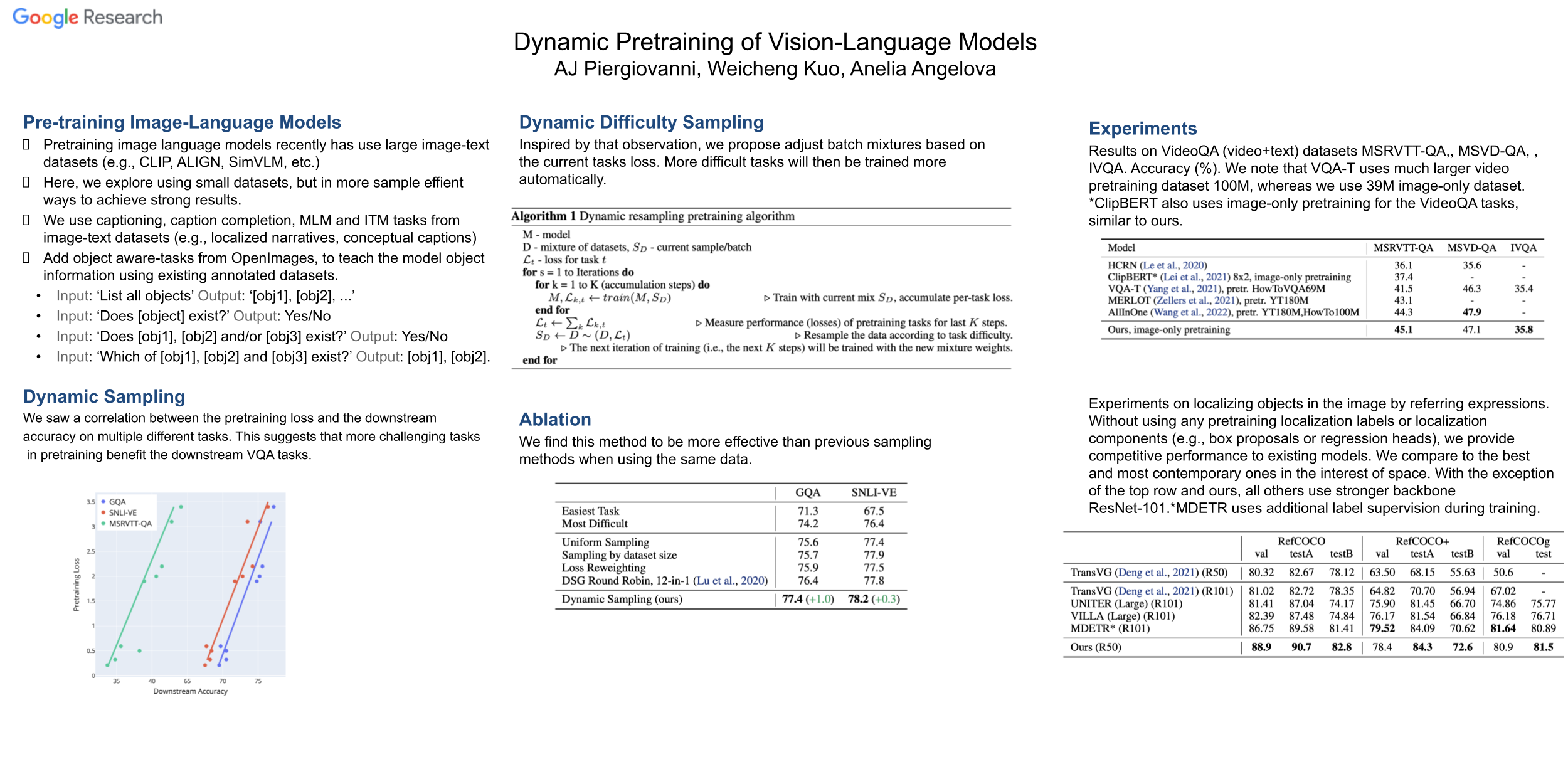
Vision-Language pretraining aims to learn universal cross-modal representations and to create models with broad capabilities. While most models have taken the direction of scaling training to increasingly large models and datasets, in this paper, we propose a dynamic pretraining resampling approach which utilizes a variety of pretraining tasks, and which results in more sample-efficient models. We show that a set of diverse self- and weakly-supervised pretraining tasks dynamically sampled according to task difficulty provides strong performance. We show that a single 330M param pretrained model using only smaller and publicly accessible image-language datasets, achieves competitive or SOTA performance on three diverse groups of tasks: visual question answering, text-based image localization by referring expressions, and video question answering.