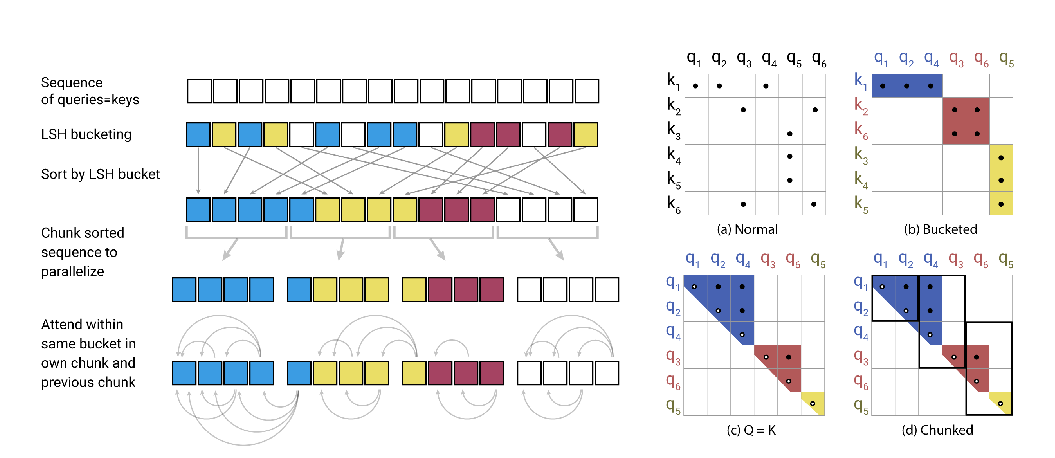
Lite Transformer with Long-Short Range Attention
Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, Song Han,
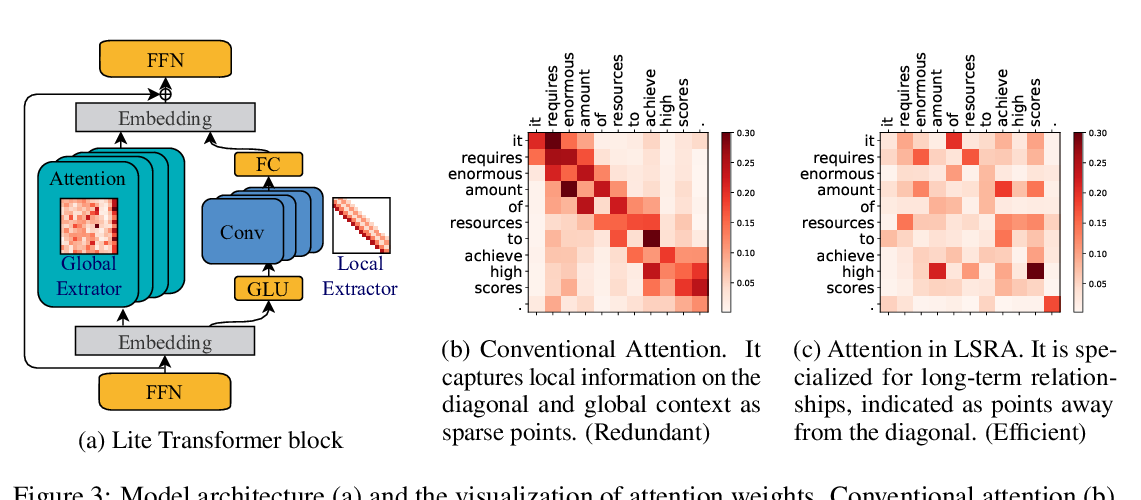
Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention
Chen Zhao, Chenyan Xiong, Corby Rosset, Xia Song, Paul Bennett, Saurabh Tiwary,
Keywords: compression, language modeling, memory, nlp, transformer