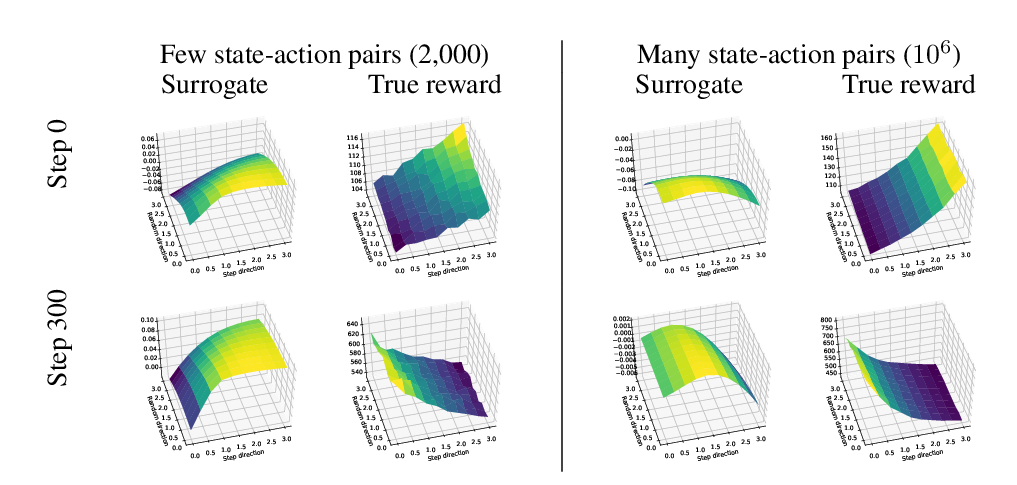
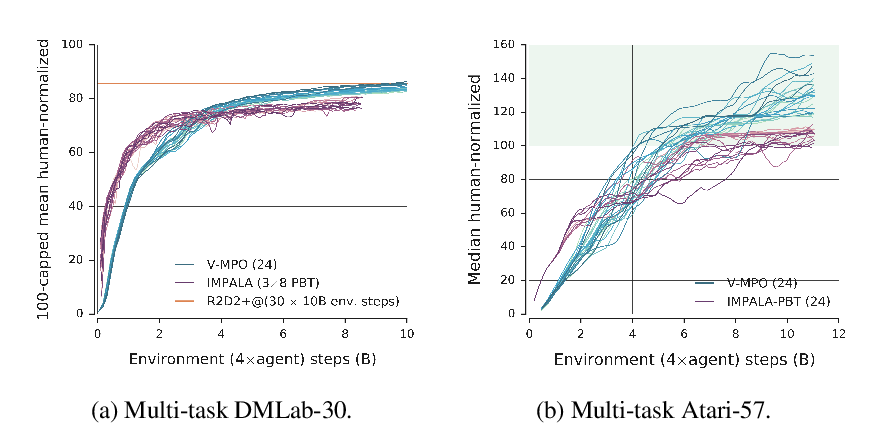
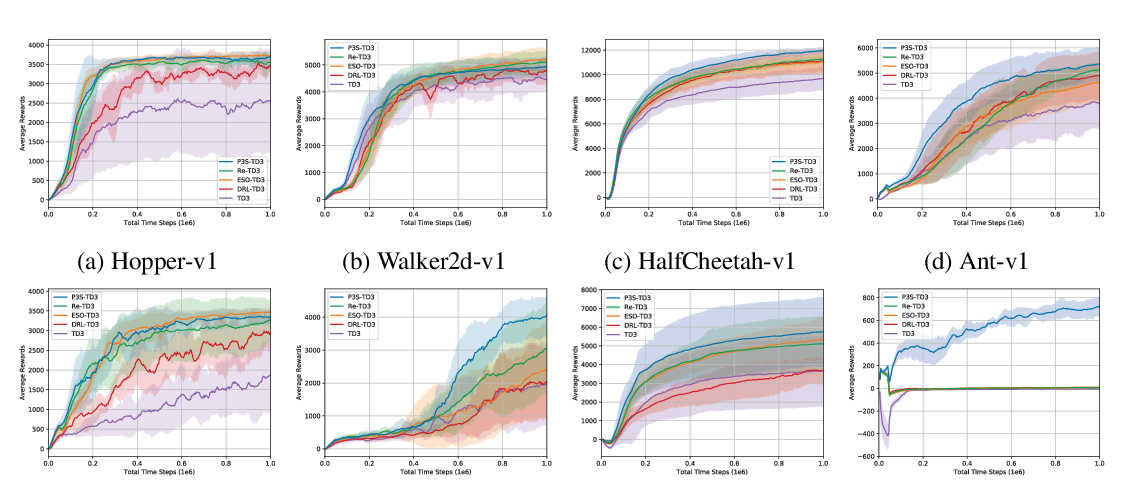
Abstract:
We study the roots of algorithmic progress in deep policy gradient algorithms through a case study on two popular algorithms, Proximal Policy Optimization and Trust Region Policy Optimization. We investigate the consequences of "code-level optimizations:" algorithm augmentations found only in implementations or described as auxiliary details to the core algorithm. Seemingly of secondary importance, such optimizations have a major impact on agent behavior. Our results show that they (a) are responsible for most of PPO's gain in cumulative reward over TRPO, and (b) fundamentally change how RL methods function. These insights show the difficulty, and importance, of attributing performance gains in deep reinforcement learning.