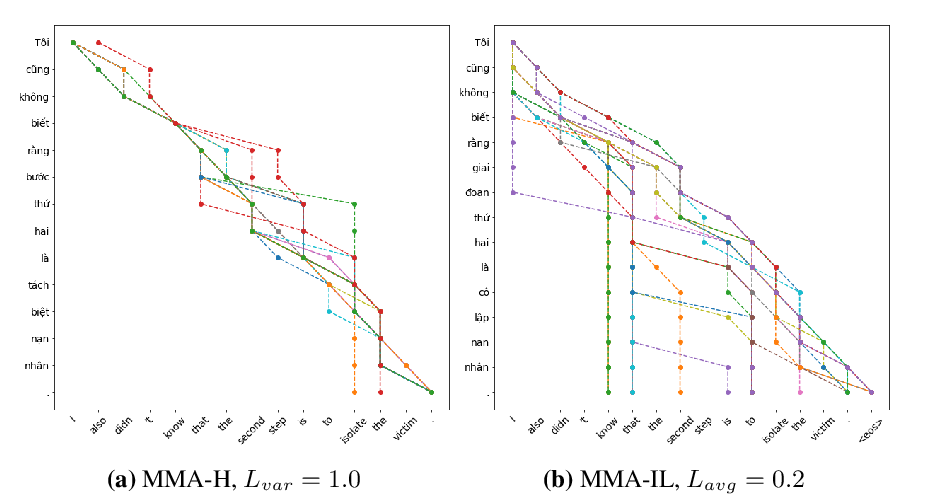
On Identifiability in Transformers
Gino Brunner, Yang Liu, Damian Pascual, Oliver Richter, Massimiliano Ciaramita, Roger Wattenhofer,
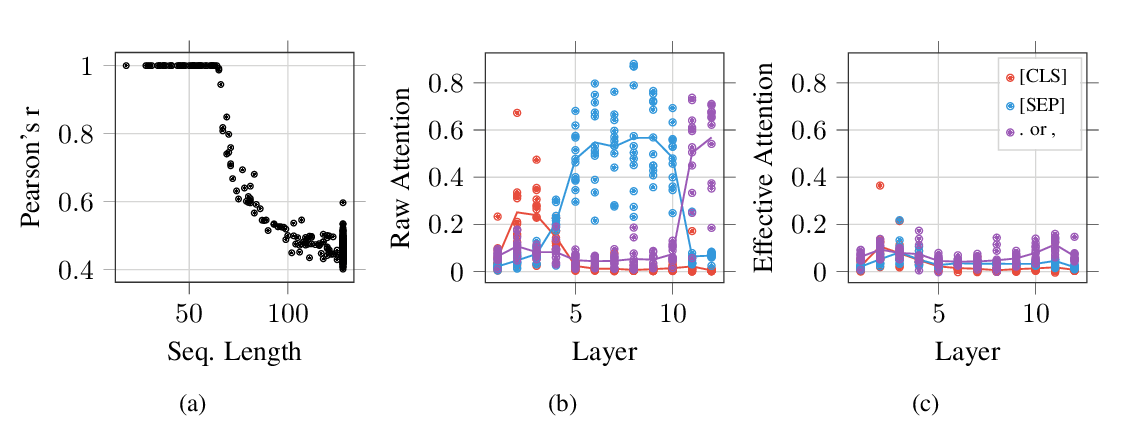
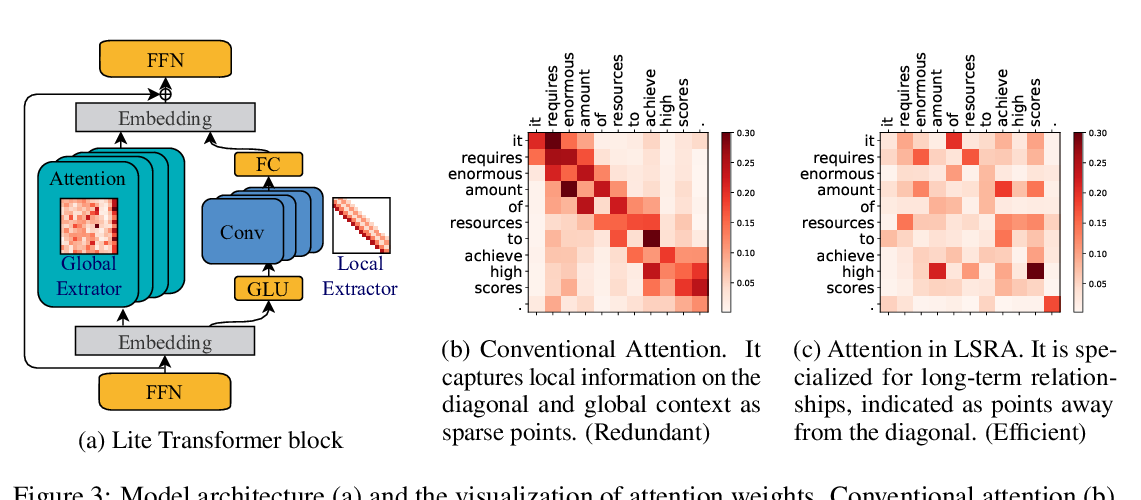
Lite Transformer with Long-Short Range Attention
Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, Song Han,
Keywords: attention, inductive bias, logic, logical reasoning, reasoning, reinforcement learning, transformer