Knowledge Distillation Through Time For Future Event Prediction
in
Affinity Event: Tiny Papers Poster Session 8
{kind=link}
Abstract
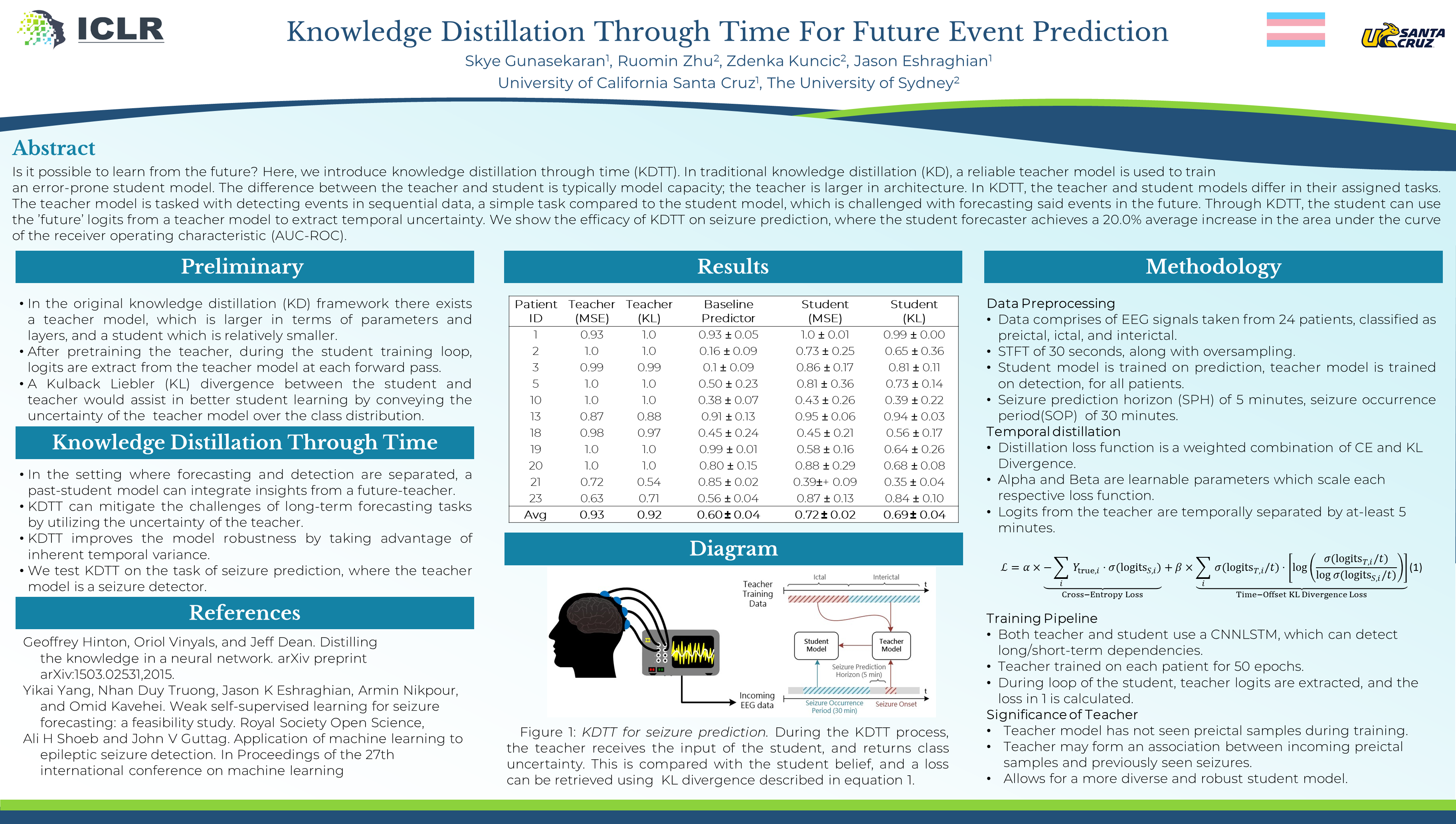
Is it possible to learn from the future? Here, we introduce knowledge distillation through time (KDTT). In traditional knowledge distillation (KD), a reliable teacher model is used to train an error-prone student model. The difference between the teacher and student is typically model capacity, where the teacher network is larger in architecture. In our KDTT framework, the teacher and student models differ in their assigned tasks: the teacher model is tasked with detecting events in sequential data, a relatively simple task relative to the student model, which is challenged with forecasting said events in the future. Through KDTT, the student can use the ‘future’ logits from a teacher model to extract a temporal representation of uncertainty. We show the efficacy of KDTT on seizure prediction models, where the student forecaster achieves over a 20% average increase in the area under the curve of the receiver operating characteristic (AUC-ROC).