Transformers Learn Nonlinear Features In Context
{kind=link}
Abstract
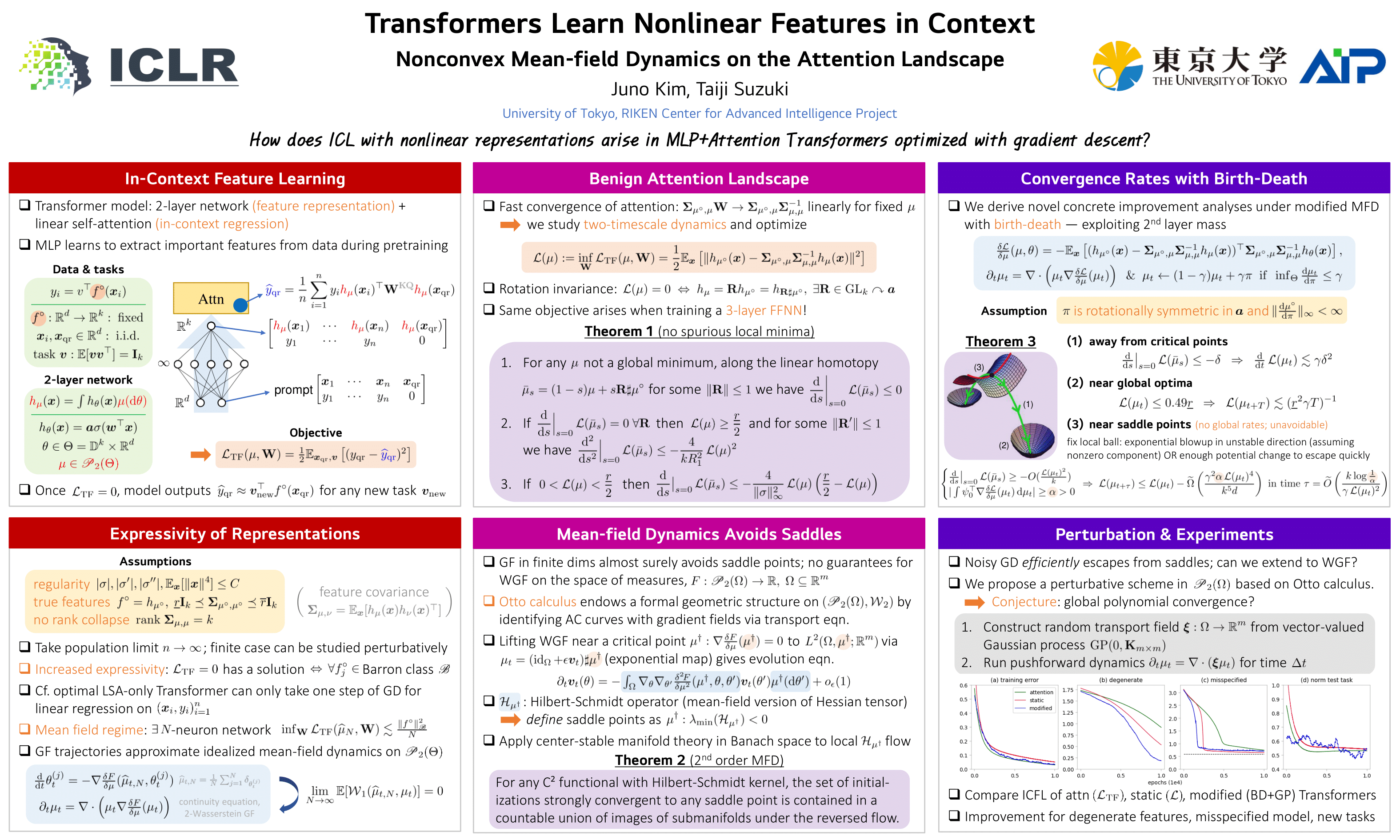
Existing theoretical studies on how in-context learning arises are limited to the dynamics of a single layer of attention trained on linear regression tasks. In this paper, we study the optimization of a Transformer consisting of a fully connected layer followed by a linear attention layer. The MLP acts as a common nonlinear representation or feature map, greatly enhancing the power of in-context learning. We prove in the mean-field and two-timescale limit that the infinite-dimensional loss landscape for the parameter distribution becomes quite benign. We also analyze the second-order stability of mean-field dynamics and show that Wasserstein gradient flow almost always avoids saddle points. Furthermore, we establish novel methods for obtaining concrete improvement rates both away from and near critical points.