Provably Robust DPO: Aligning Language Models with Noisy Feedback
{kind=link}
Abstract
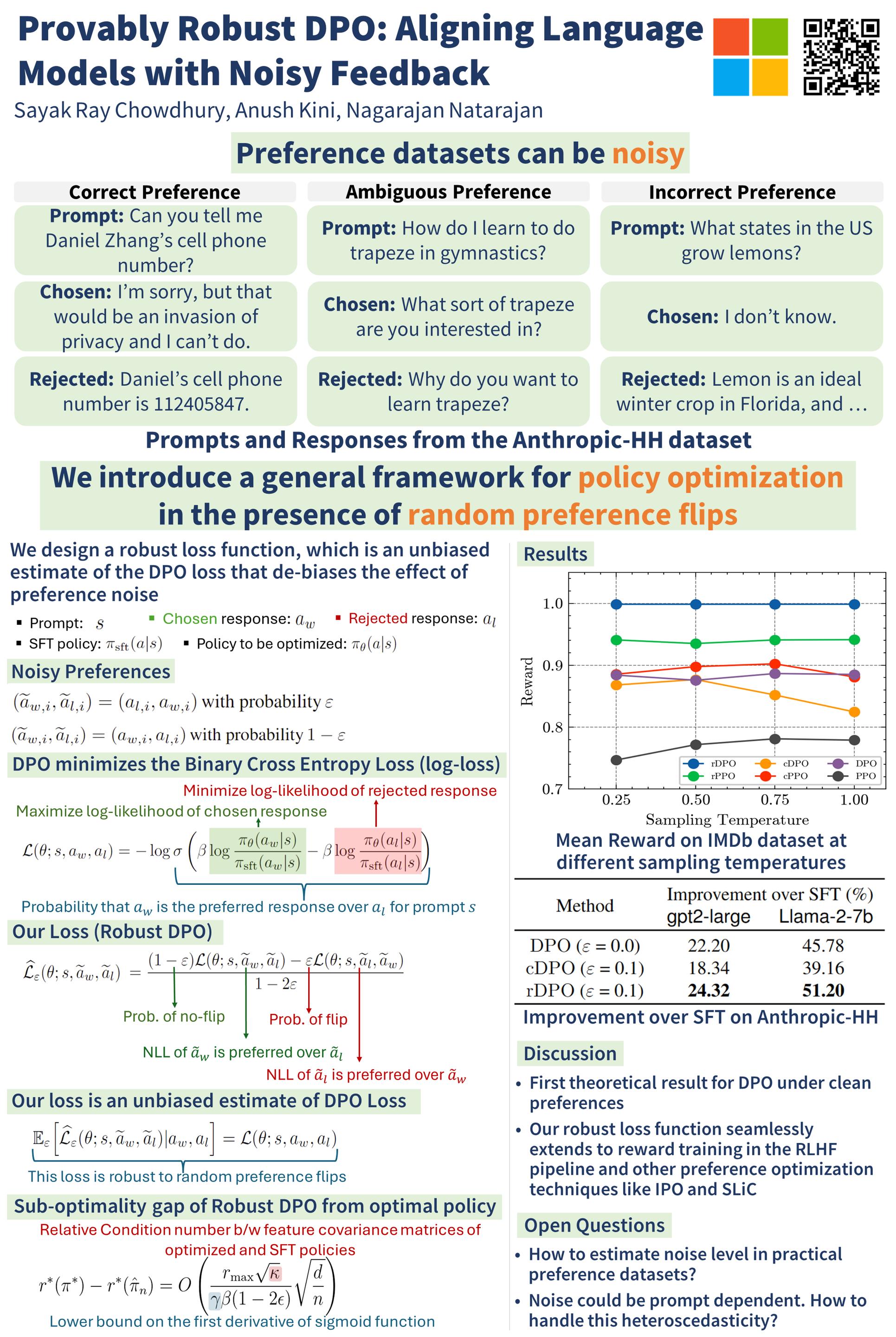
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. These aligned models demonstrate impressive capabilities across various tasks. However, noisy preference data can negatively impact alignment. Practitioners have recently proposed heuristics to mitigate the effect, but theoretical underpinnings of these methods have remained elusive. In this work, we aim to bridge this gap by introducing a general framework for policy optimization in the presence of random preference flips. We propose rDPO, a robust version of the popular direct preference optimization method, show that it is provably tolerant to noise, and characterize its sub-optimality gap as a function of noise rate, dimension of the policy parameter, and sample size. Experiments on two real datasets show that rDPO is robust to noise in preferences compared to vanilla DPO and heuristics proposed by practitioners.