BOLAA: BENCHMARKING AND ORCHESTRATING LLM AUTONOMOUS AGENTS
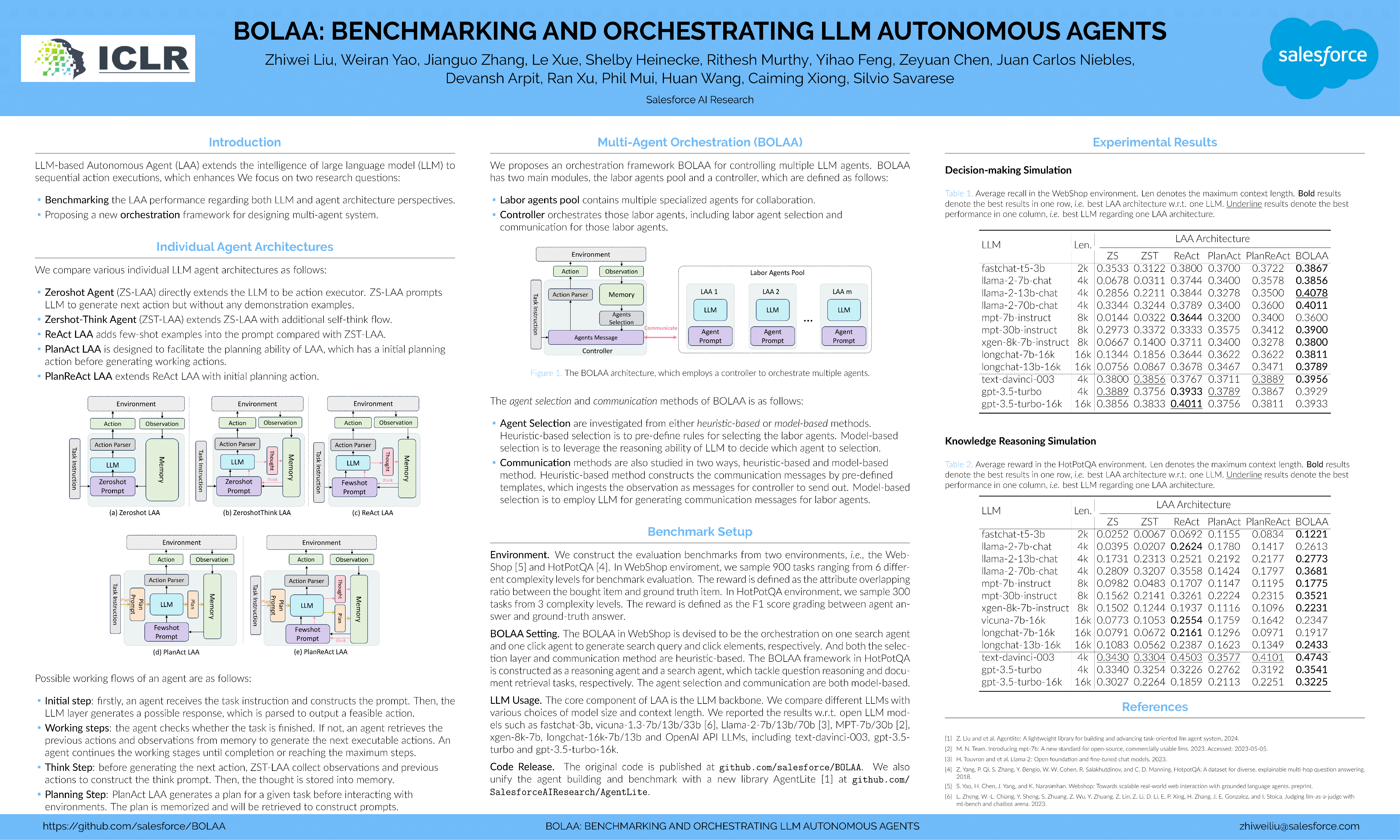{kind=link}
Abstract
The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs).An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions.Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones.Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, i.e. BOLAA, where a controller manages the communication among multiple agents.We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs.Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both.