Un-Mixing Test-Time Normalization Statistics: Combatting Label Temporal Correlation
Devavrat Tomar ⋅ Guillaume Vray ⋅ Jean-Philippe Thiran ⋅ Behzad Bozorgtabar
2024 Poster
{kind=link}
Abstract
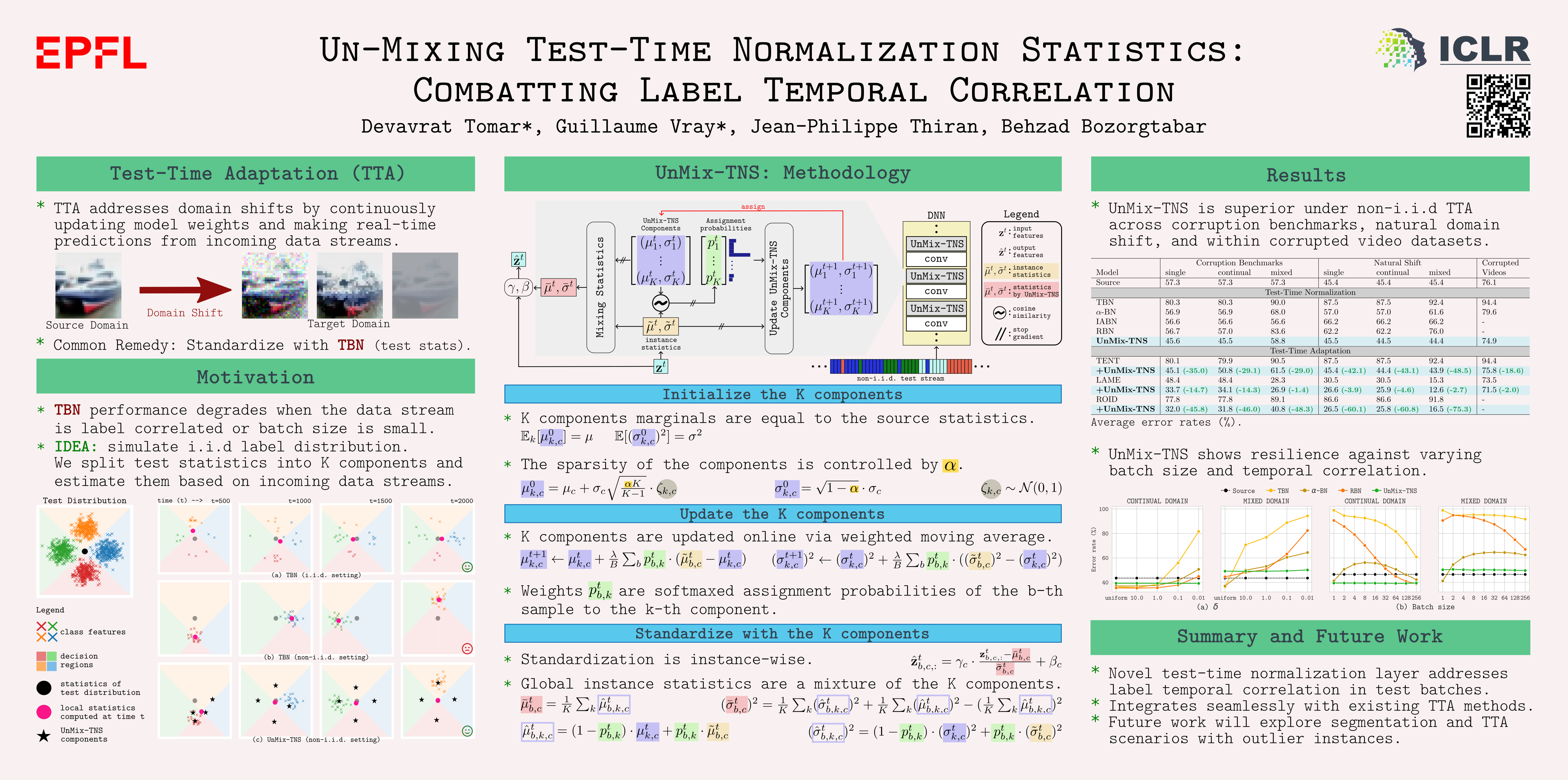
Recent test-time adaptation methods heavily rely on nuanced adjustments of batch normalization (BN) parameters. However, one critical assumption often goes overlooked: that of independently and identically distributed (i.i.d.) test batches with respect to unknown labels. This oversight leads to skewed BN statistics and undermines the reliability of the model under non-i.i.d. scenarios. To tackle this challenge, this paper presents a novel method termed '$\textbf{Un-Mix}$ing $\textbf{T}$est-Time $\textbf{N}$ormalization $\textbf{S}$tatistics' (UnMix-TNS). Our method re-calibrates the statistics for each instance within a test batch by $\textit{mixing}$ it with multiple distinct statistics components, thus inherently simulating the i.i.d. scenario. The core of this method hinges on a distinctive online $\textit{unmixing}$ procedure that continuously updates these statistics components by incorporating the most similar instances from new test batches. Remarkably generic in its design, UnMix-TNS seamlessly integrates with a wide range of leading test-time adaptation methods and pre-trained architectures equipped with BN layers. Empirical evaluations corroborate the robustness of UnMix-TNS under varied scenarios—ranging from single to continual and mixed domain shifts, particularly excelling with temporally correlated test data and corrupted non-i.i.d. real-world streams. This adaptability is maintained even with very small batch sizes or single instances. Our results highlight UnMix-TNS's capacity to markedly enhance stability and performance across various benchmarks. Our code is publicly available at https://github.com/devavratTomar/unmixtns.
Video
Chat is not available.
Successful Page Load