Toward Student-oriented Teacher Network Training for Knowledge Distillation
{kind=link}
Abstract
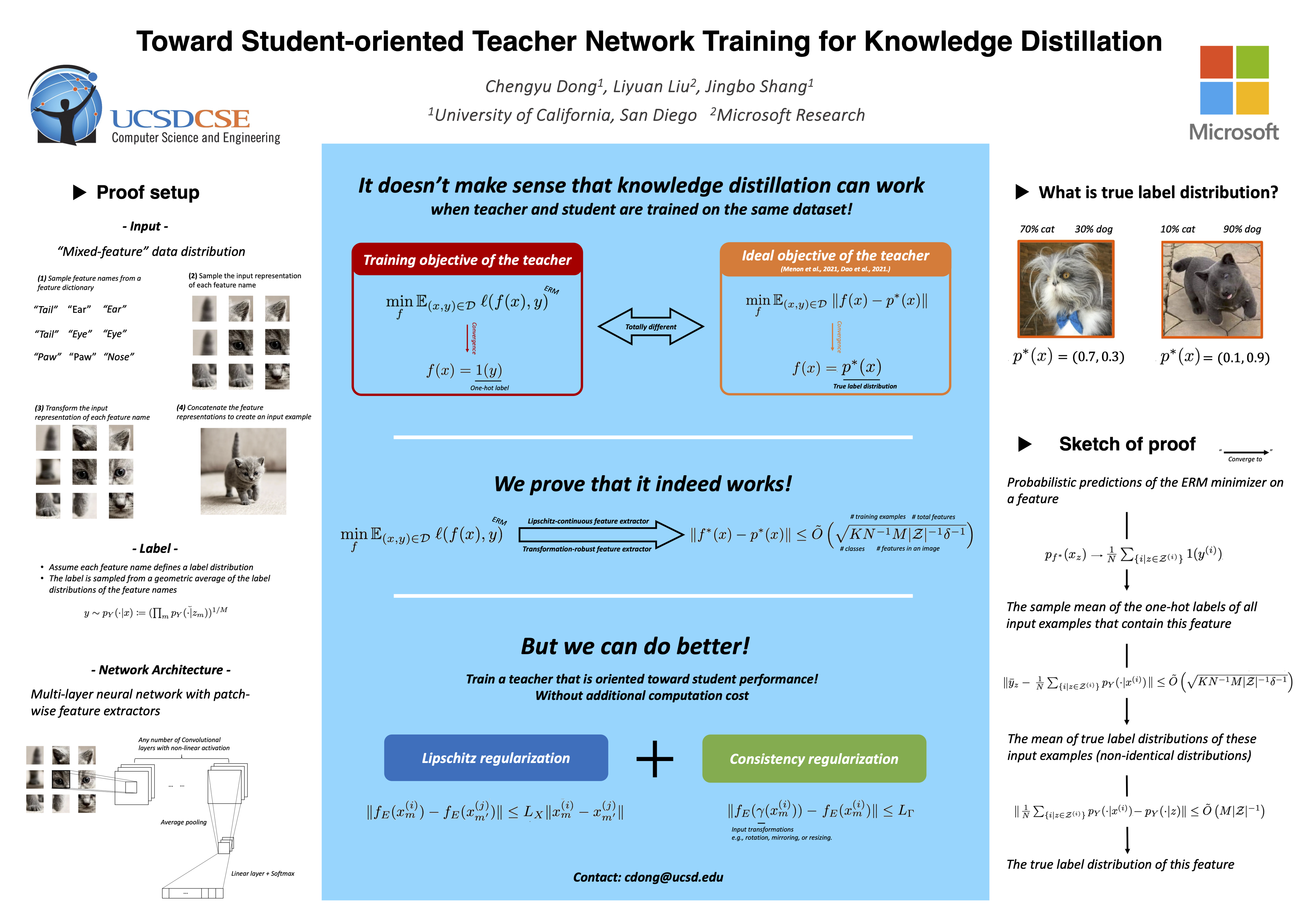
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher’s capability to approximate the true label distribution of training inputs. We theoretically establish that ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.