Skip-Attention: Improving Vision Transformers by Paying Less Attention
{kind=link}
Abstract
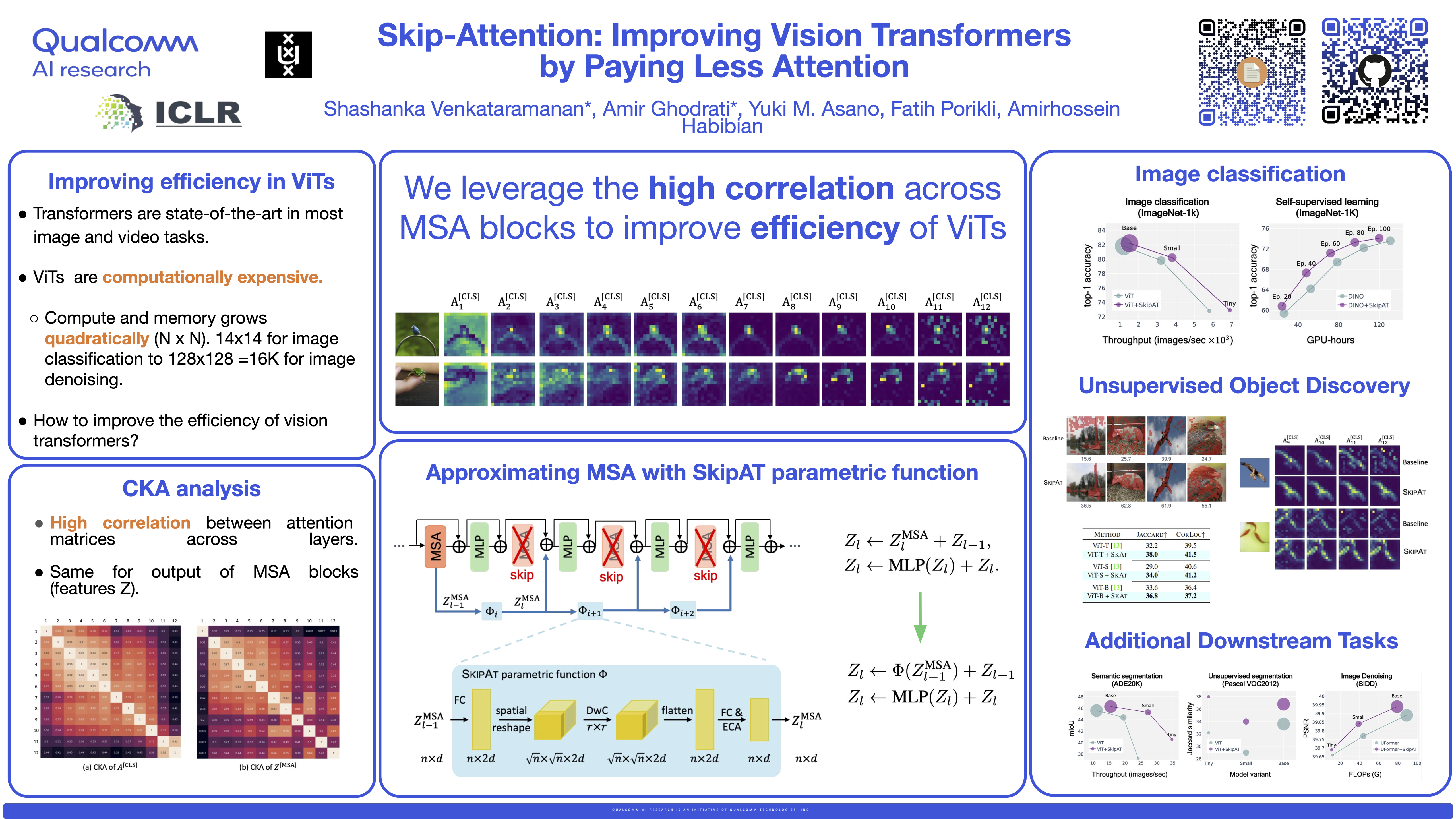
This work aims to improve the efficiency of vision transformers (ViTs). While ViTs use computationally expensive self-attention operations in every layer, we identify that these operations are highly correlated across layers -- a key redundancy that causes unnecessary computations. Based on this observation, we propose SkipAT a method to reuse self-attention computation from preceding layers to approximate attention at one or more subsequent layers. To ensure that reusing self-attention blocks across layers does not degrade the performance, we introduce a simple parametric function, which outperforms the baseline transformer's performance while running computationally faster. We show that SkipAT is agnostic to transformer architecture and is effective in image classification, semantic segmentation on ADE20K, image denoising on SIDD, and video denoising on DAVIS. We achieve improved throughput at the same-or-higher accuracy levels in all these tasks.