Connect, Collapse, Corrupt: Learning Cross-Modal Tasks with Uni-Modal Data
Yuhui Zhang ⋅ Elaine Sui ⋅ Serena Yeung
2024 Poster
{kind=link}
Abstract
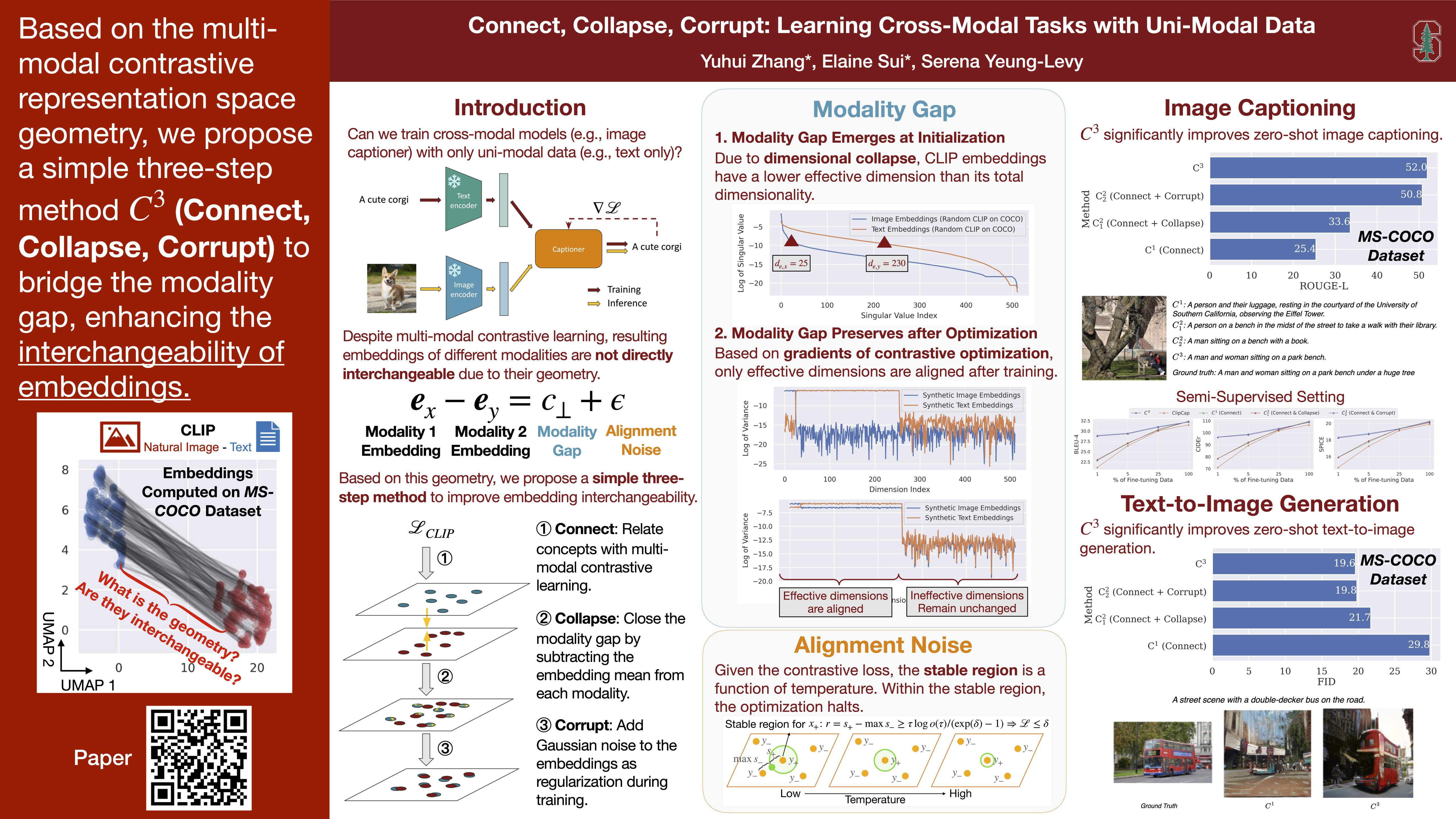
Building cross-modal applications is challenging due to limited paired multi-modal data. Recent works have shown that leveraging a pre-trained multi-modal contrastive representation space enables cross-modal tasks to be learned from uni-modal data. This is based on the assumption that contrastive optimization makes embeddings from different modalities interchangeable. However, this assumption is under-explored due to the poorly understood geometry of the multi-modal contrastive space, where a modality gap exists. In our study, we provide a theoretical explanation of this space's geometry and introduce a three-step method, $C^3$ (Connect, Collapse, Corrupt), to bridge the modality gap, enhancing the interchangeability of embeddings. Our $C^3$ method significantly improves cross-modal learning from uni-modal data, achieving state-of-the-art results on zero-shot image / audio / video captioning and text-to-image generation.
Video
Chat is not available.
Successful Page Load