Learning to Act without Actions
{kind=link}
Abstract
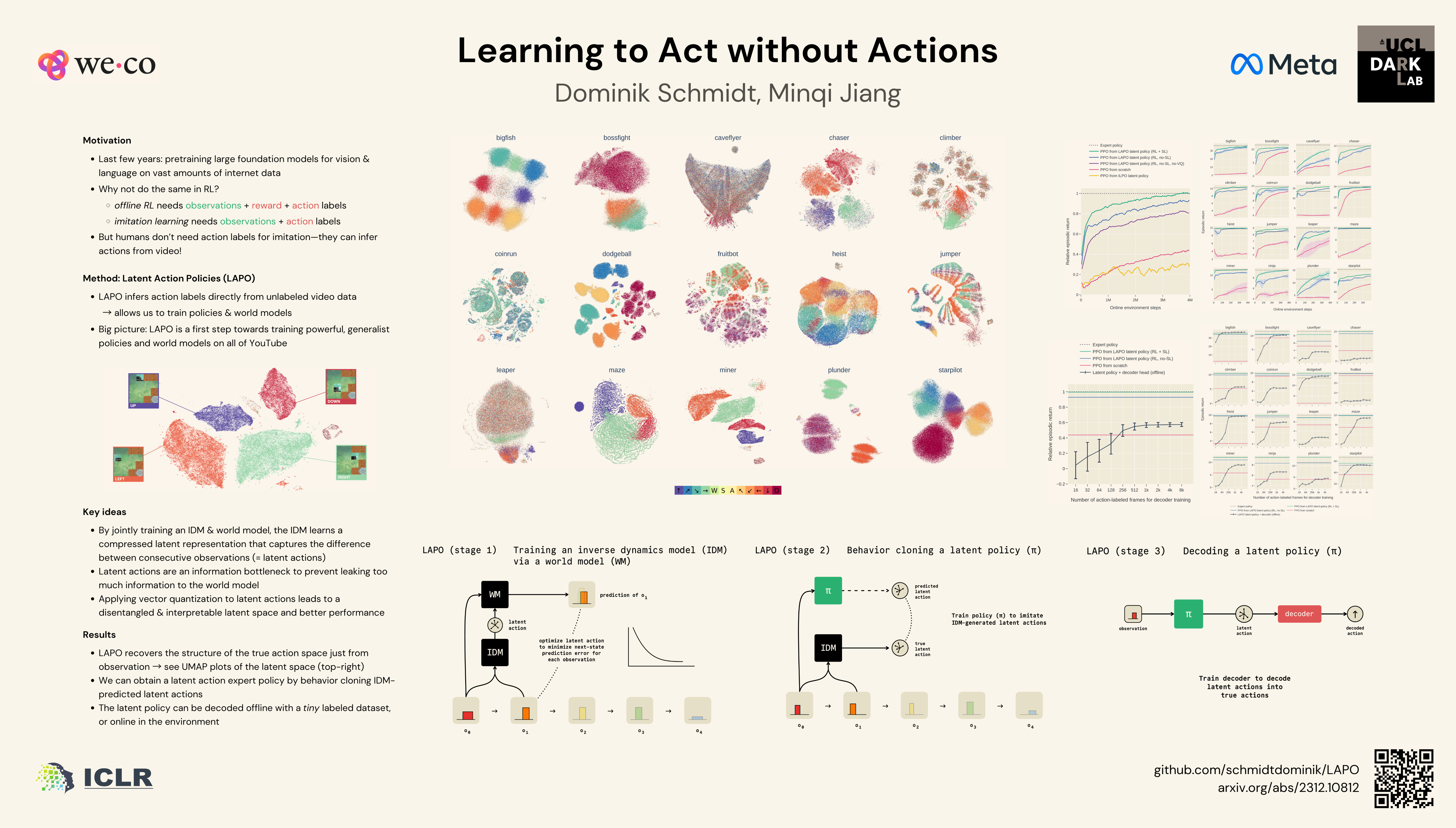
Pre-training large models on vast amounts of web data has proven to be an effective approach for obtaining powerful, general models in domains such as language and vision. However, this paradigm has not yet taken hold in reinforcement learning. This is because videos, the most abundant form of embodied behavioral data on the web, lack the action labels required by existing methods for imitating behavior from demonstrations. We introduce Latent Action Policies (LAPO), a method for recovering latent action information—and thereby latent-action policies, world models, and inverse dynamics models—purely from videos. LAPO is the first method able to recover the structure of the true action space just from observed dynamics, even in challenging procedurally-generated environments. LAPO enables training latent-action policies that can be rapidly fine-tuned into expert-level policies, either offline using a small action-labeled dataset, or online with rewards. LAPO takes a first step towards pre-training powerful, generalist policies and world models on the vast amounts of videos readily available on the web. Our code is available here: https://github.com/schmidtdominik/LAPO.