DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Yongchao Zhou ⋅ Kaifeng Lyu ⋅ Ankit Singh Rawat ⋅ Aditya Krishna Menon ⋅ Afshin Rostamizadeh ⋅ Sanjiv Kumar ⋅ Jean-François Kagy ⋅ Rishabh Agarwal
2024 Poster
{kind=link}
Abstract
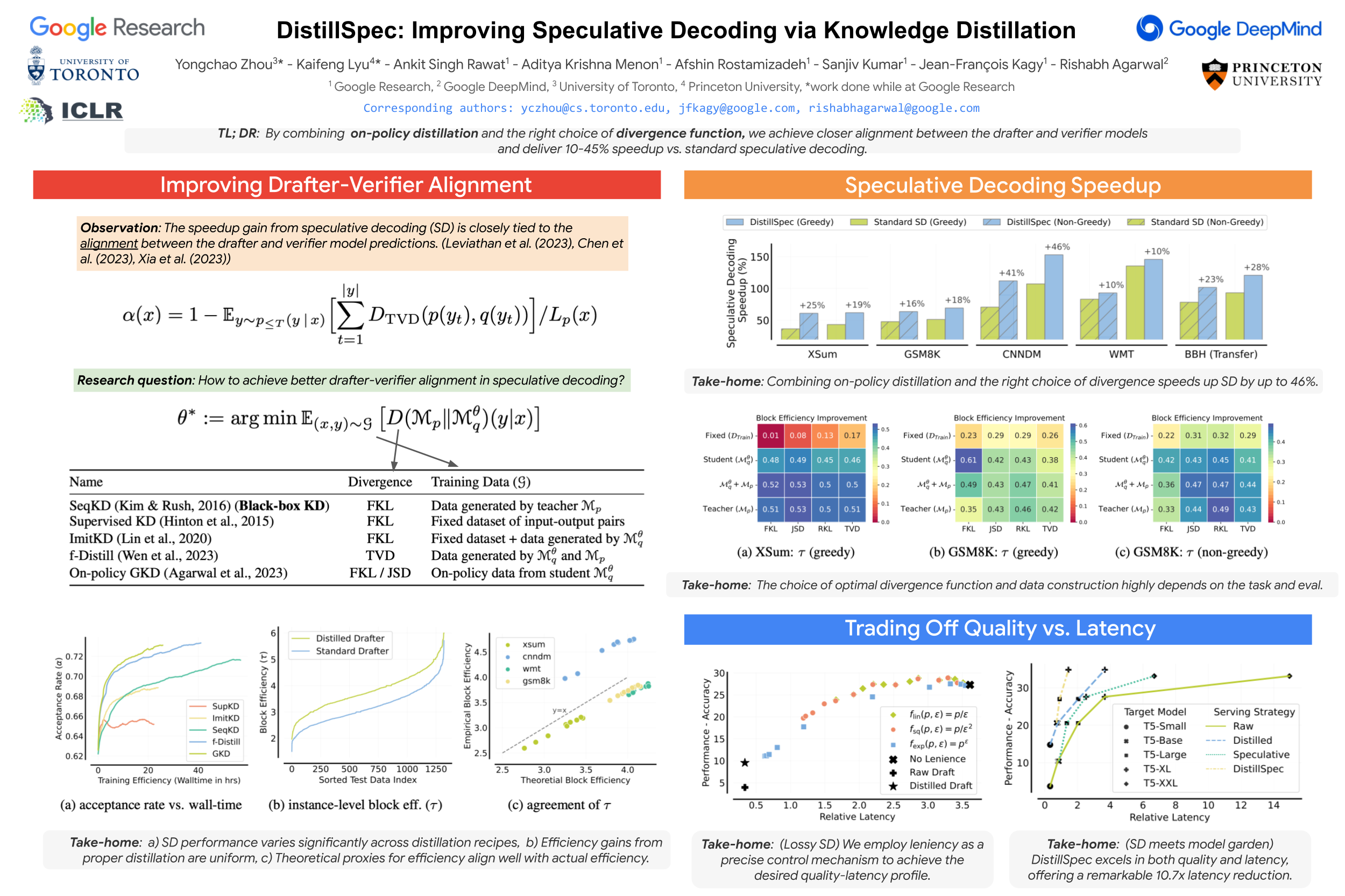
Speculative decoding~(SD) accelerates large language model inference by employing a faster {\em draft} model for generating multiple tokens, which are then verified in parallel by the larger {\em target} model, resulting in the text generated according to the target model distribution. However, identifying a compact draft model that is well-aligned with the target model is challenging. To tackle this issue, we propose {\em DistillSpec} that uses knowledge distillation to better align the draft model with the target model, before applying SD. DistillSpec makes two key design choices, which we demonstrate via systematic study to be crucial to improve the draft and target alignment: utilizing \emph{on-policy} data generation from the draft model, and \emph{tailoring the divergence function} to the task and decoding strategy. Notably, DistillSpec yields impressive $10 - 45\%$ speedups over standard SD on a range of standard benchmarks, using both greedy and non-greedy sampling. Furthermore, we combine DistillSpec with lossy SD to achieve fine-grained control over the latency vs. task performance trade-off. Finally, in practical scenarios with models of varying sizes, first using distillation to boost the performance of the target model and then applying DistillSpec to train a well-aligned draft model can reduce decoding latency by $6 - 10\times$ with minimal performance drop, compared to standard decoding without distillation.
Video
Chat is not available.
Successful Page Load