Does Progress On Object Recognition Benchmarks Improve Generalization on Crowdsourced, Global Data?
Megan Richards ⋅ Polina Kirichenko ⋅ Diane Bouchacourt ⋅ Mark Ibrahim
2024 Poster
{kind=link}
Abstract
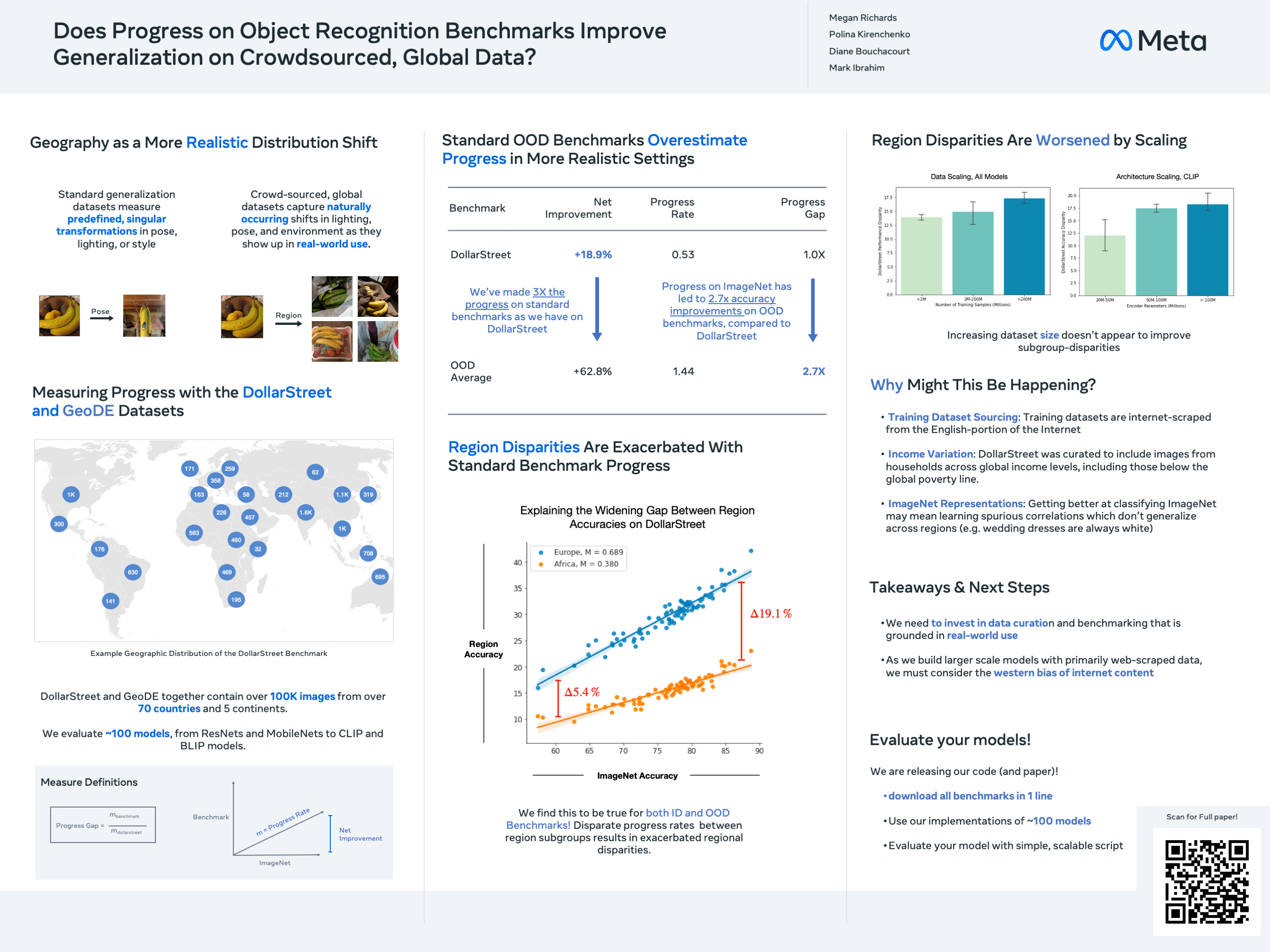
For more than a decade, researchers have measured progress in object recognition on the ImageNet dataset along with its associated generalization benchmarks such as ImageNet-A, -C, and -R. Recent advances in foundation models, trained on orders of magnitude more data, have begun to saturate performance on these benchmarks. Despite this progress, even today’s best models are brittle in practice. As a step toward more holistic measurement of model reliability, we propose studying performance on crowdsourced, global datasets, which contain natural distribution shifts seen practically in deployment. We perform a comprehensive empirical study on two crowdsourced, globally representative datasets, evaluating nearly 100 vision models to uncover several concerning empirical trends: first, that progress on crowdsourced, global data has significantly lagged behind standard benchmarks, with advances on ImageNet occurring at $2.5x$ the rate of progress on crowdsourced, global data. Second, we find that progress on standard benchmarks has failed to improve or exacerbated geographic disparities: geographic disparities between the least performant models and today's best models have more than tripled. We showcase the promise of using more curated and/or representative training datasets for mitigating these trends, and emphasize curation of web-scale, geographically representative training datasets as a critical open problem for the research community.
Video
Chat is not available.
Successful Page Load