Beyond task performance: evaluating and reducing the flaws of large multimodal models with in-context-learning
{kind=link}
Abstract
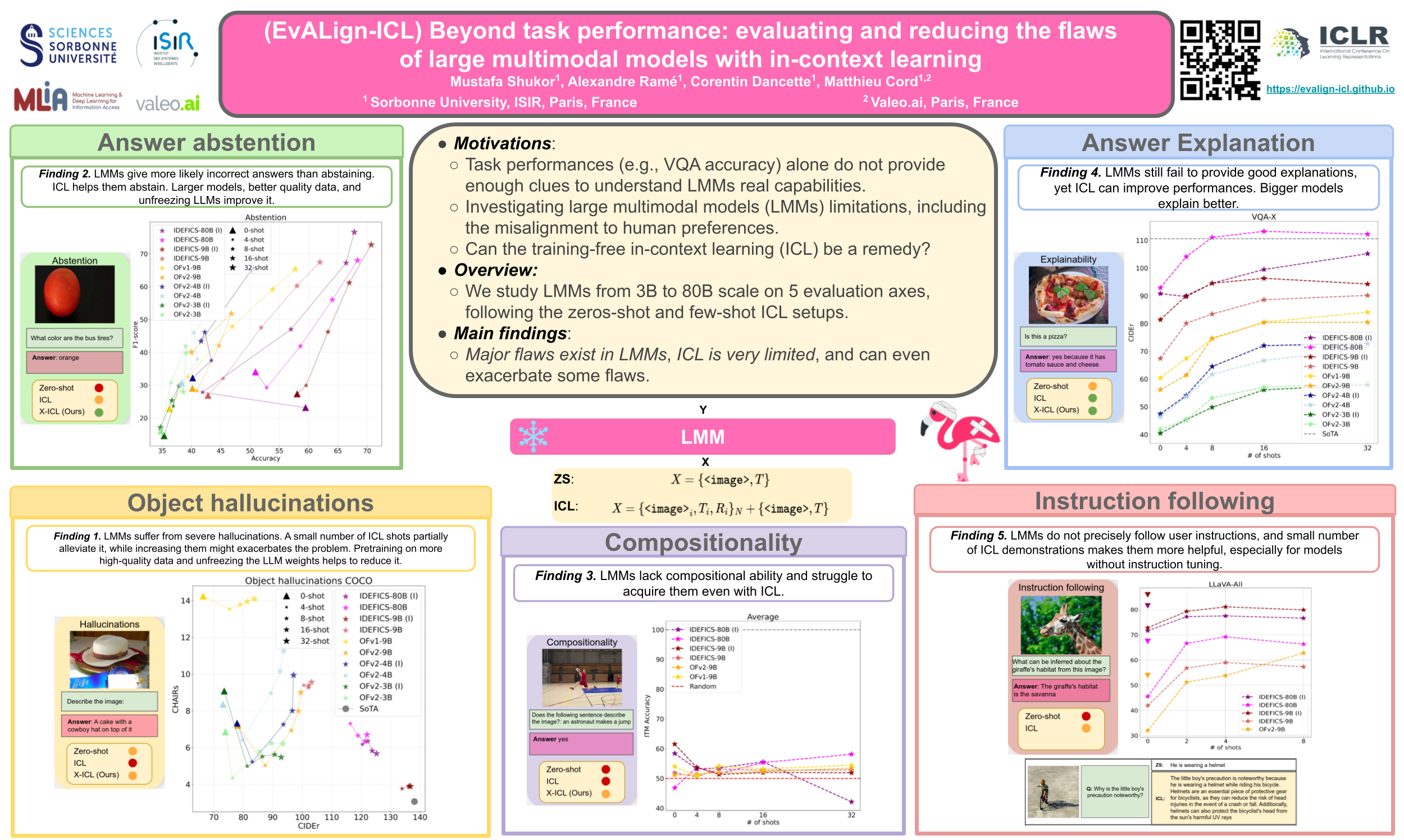
Following the success of Large Language Models (LLMs), Large Multimodal Models (LMMs), such as the Flamingo model and its subsequent competitors, have started to emerge as natural steps towards generalist agents. However, interacting with recent LMMs reveals major limitations that are hardly captured by the current evaluation benchmarks. Indeed, task performances (e.g., VQA accuracy) alone do not provide enough clues to understand their real capabilities, limitations, and to which extent such models are aligned to human expectations. To refine our understanding of those flaws, we deviate from the current evaluation paradigm, and (1) evaluate 10 recent open-source LMMs from 3B up to 80B parameter scale, on 5 different axes; hallucinations, abstention, compositionality, explainability and instruction following. Our evaluation on these axes reveals major flaws in LMMs. While the current go-to solution to align these models is based on training, such as instruction tuning or RLHF, we rather (2) explore the training-free in-context learning (ICL) as a solution, and study how it affects these limitations. Based on our ICL study, (3) we push ICL further and propose new multimodal ICL variants such as; Multitask-ICL, Chain-of-Hindsight-ICL, and Self-Correcting-ICL. Our findings are as follows; (1) Despite their success, LMMs have flaws that remain unsolved with scaling alone. (2) The effect of ICL on LMMs flaws is nuanced; despite its effectiveness for improved explainability, answer abstention, ICL only slightly improves instruction following, does not improve compositional abilities, and actually even amplifies hallucinations. (3) The proposed ICL variants are promising as post-hoc approaches to efficiently tackle some of those flaws. The code is available here: https://github.com/mshukor/EvALign-ICL.