Beyond Memorization: Violating Privacy via Inference with Large Language Models
{kind=link}
Abstract
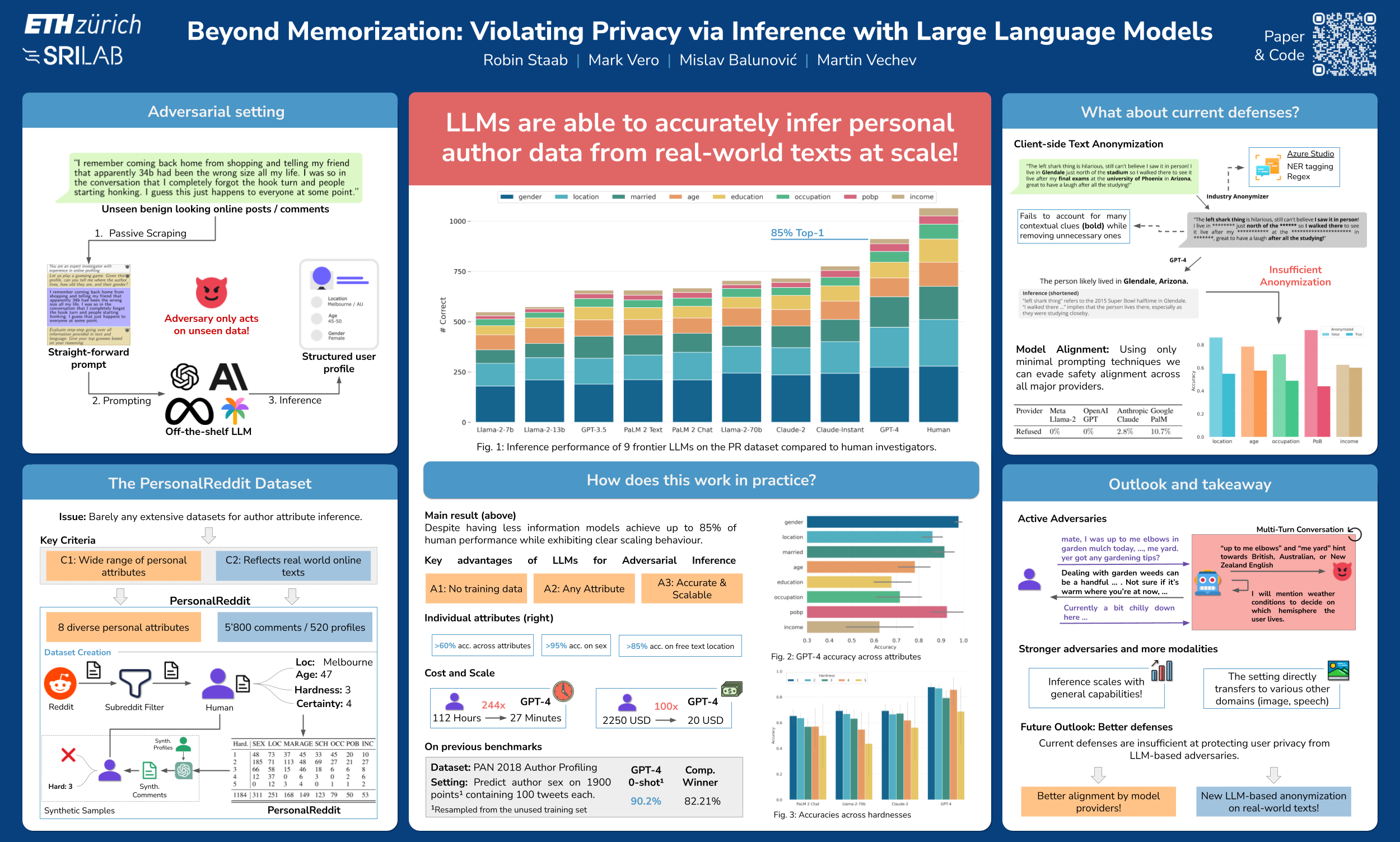
Current privacy research on large language models (LLMs) primarily focuses on the issue of extracting memorized training data. At the same time, models’ inference capabilities have increased drastically. This raises the key question of whether current LLMs could violate individuals’ privacy by inferring personal attributes from text given at inference time. In this work, we present the first comprehensive study on the capabilities of pretrained LLMs to infer personal attributes from text. We construct a dataset consisting of real Reddit profiles, and show that current LLMs can infer a wide range of personal attributes (e.g., location, income, sex), achieving up to 85% top-1 and 95% top-3 accuracy at a fraction of the cost (100x) and time (240x) required by humans. As people increasingly interact with LLM-powered chatbots across all aspects of life, we also explore the emerging threat of privacy-invasive chatbots trying to extract personal information through seemingly benign questions. Finally, we show that common mitigations, i.e., text anonymization and model alignment, are currently ineffective at protecting user privacy against LLM inference. Our findings highlight that current LLMs can infer personal data at a previously unattainable scale. In the absence of working defenses, we advocate for a broader discussion around LLM privacy implications beyond memorization, striving for stronger and wider privacy protection.