BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
{kind=link}
Abstract
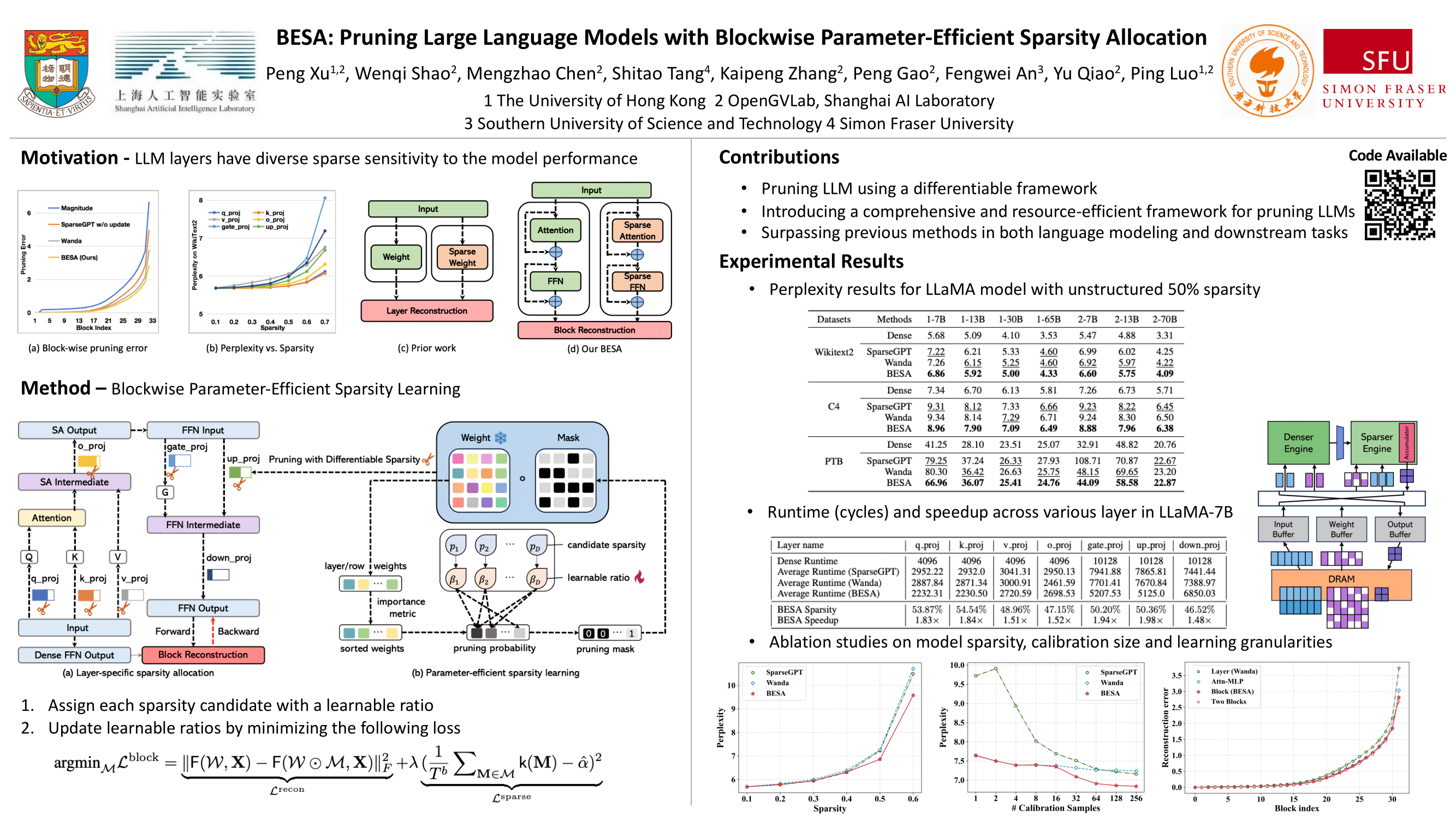
Large language models (LLMs) have demonstrated outstanding performance in various tasks, such as text summarization, text question-answering, and etc. While their performance is impressive, the computational footprint due to their vast number of parameters can be prohibitive. Existing solutions such as SparseGPT and Wanda attempt to alleviate this issue through weight pruning. However, their layer-wise approach results in significant perturbation to the model's output and requires meticulous hyperparameter tuning, such as the pruning rate, which can adversely affect overall model performance. To address this, this paper introduces a novel LLM pruning technique dubbed blockwise parameter-efficient sparsity allocation (BESA) by applying a blockwise reconstruction loss. In contrast to the typical layer-wise pruning techniques, BESA is characterized by two distinctive attributes: i) it targets the overall pruning error with respect to individual transformer blocks, and ii) it allocates layer-specific sparsity in a differentiable manner, both of which ensure reduced performance degradation after pruning. Our experiments show that BESA achieves state-of-the-art performance, efficiently pruning LLMs like LLaMA1, and LLaMA2 with 7B to 70B parameters on a single A100 GPU in just five hours. Code is available at here.