SEPT: Towards Efficient Scene Representation Learning for Motion Prediction
{kind=link}
Abstract
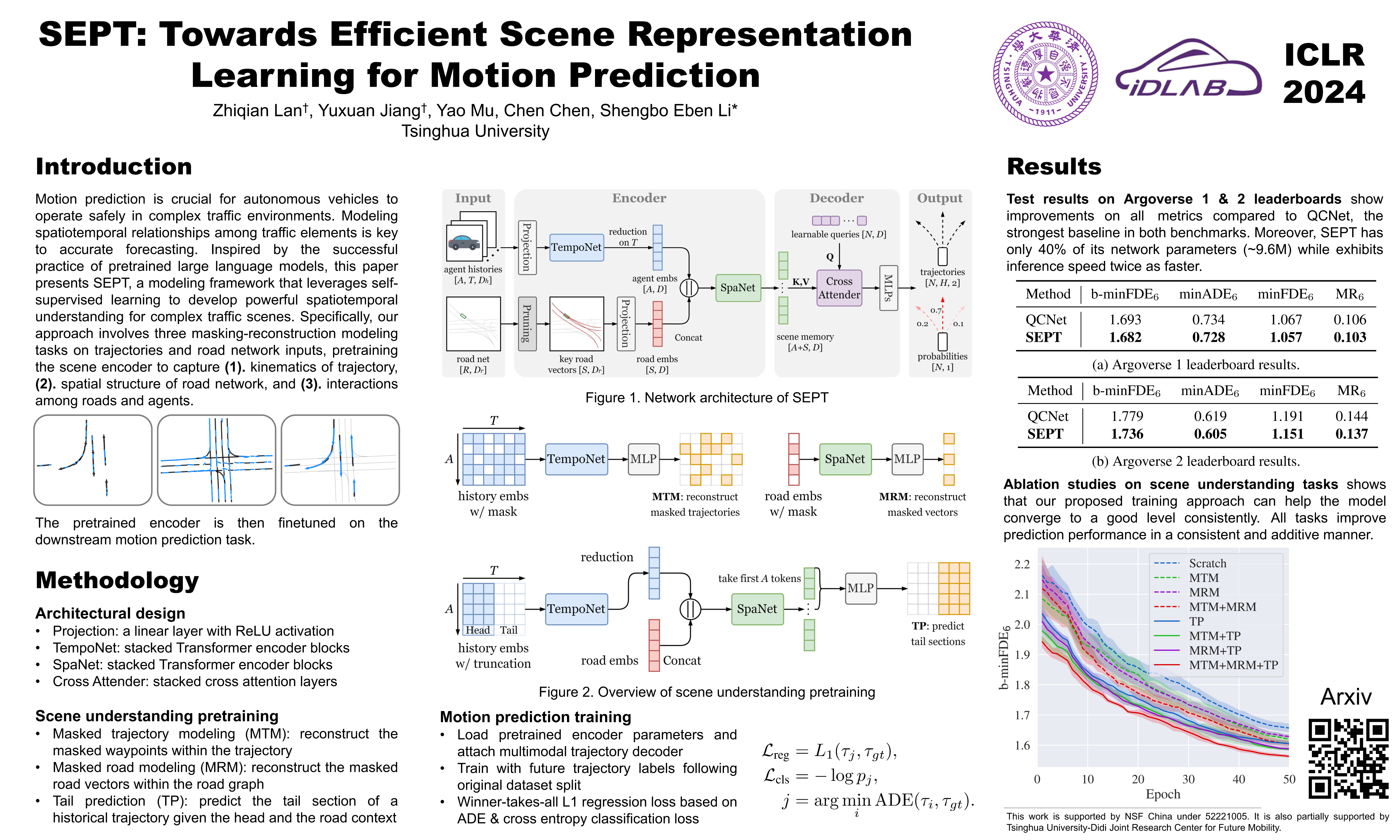
Motion prediction is crucial for autonomous vehicles to operate safely in complex traffic environments. Extracting effective spatiotemporal relationships among traffic elements is key to accurate forecasting. Inspired by the successful practice of pretrained large language models, this paper presents SEPT, a modeling framework that leverages self-supervised learning to develop powerful spatiotemporal understanding for complex traffic scenes. Specifically, our approach involves three masking-reconstruction modeling tasks on scene inputs including agents' trajectories and road network, pretraining the scene encoder to capture kinematics within trajectory, spatial structure of road network, and interactions among roads and agents. The pretrained encoder is then finetuned on the downstream forecasting task. Extensive experiments demonstrate that SEPT, without elaborate architectural design or manual feature engineering, achieves state-of-the-art performance on the Argoverse 1 and Argoverse 2 motion forecasting benchmarks, outperforming previous methods on all main metrics by a large margin.