AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model
{kind=link}
Abstract
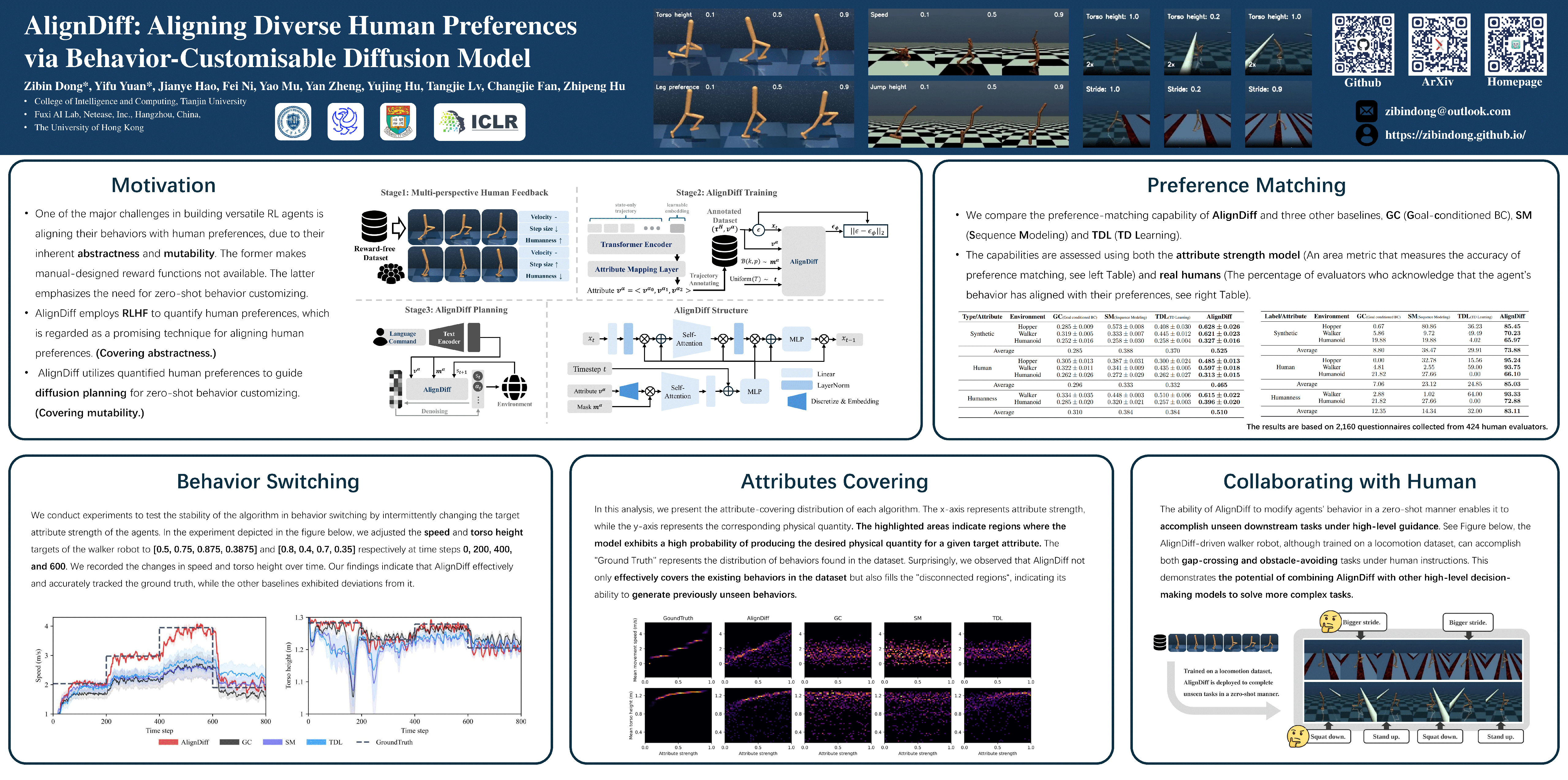
Aligning agent behaviors with diverse human preferences remains a challenging problem in reinforcement learning (RL), owing to the inherent abstractness and mutability of human preferences. To address these issues, we propose AlignDiff, a novel framework that leverages RLHF to quantify human preferences, covering abstractness, and utilizes them to guide diffusion planning for zero-shot behavior customizing, covering mutability. AlignDiff can accurately match user-customized behaviors and efficiently switch from one to another. To build the framework, we first establish the multi-perspective human feedback datasets, which contain comparisons for the attributes of diverse behaviors, and then train an attribute strength model to predict quantified relative strengths. After relabeling behavioral datasets with relative strengths, we proceed to train an attribute-conditioned diffusion model, which serves as a planner with the attribute strength model as a director for preference aligning at the inference phase. We evaluate AlignDiff on various locomotion tasks and demonstrate its superior performance on preference matching, switching, and covering compared to other baselines. Its capability of completing unseen downstream tasks under human instructions also showcases the promising potential for human-AI collaboration. More visualization videos are released on https://aligndiff.github.io/.