Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement
Linlu Qiu ⋅ Liwei Jiang ⋅ Ximing Lu ⋅ Melanie Sclar ⋅ Valentina Pyatkin ⋅ Chandra Bhagavatula ⋅ Bailin Wang ⋅ Yoon Kim ⋅ Yejin Choi ⋅ Nouha Dziri ⋅ Xiang Ren
2024 Poster
{kind=link}
Abstract
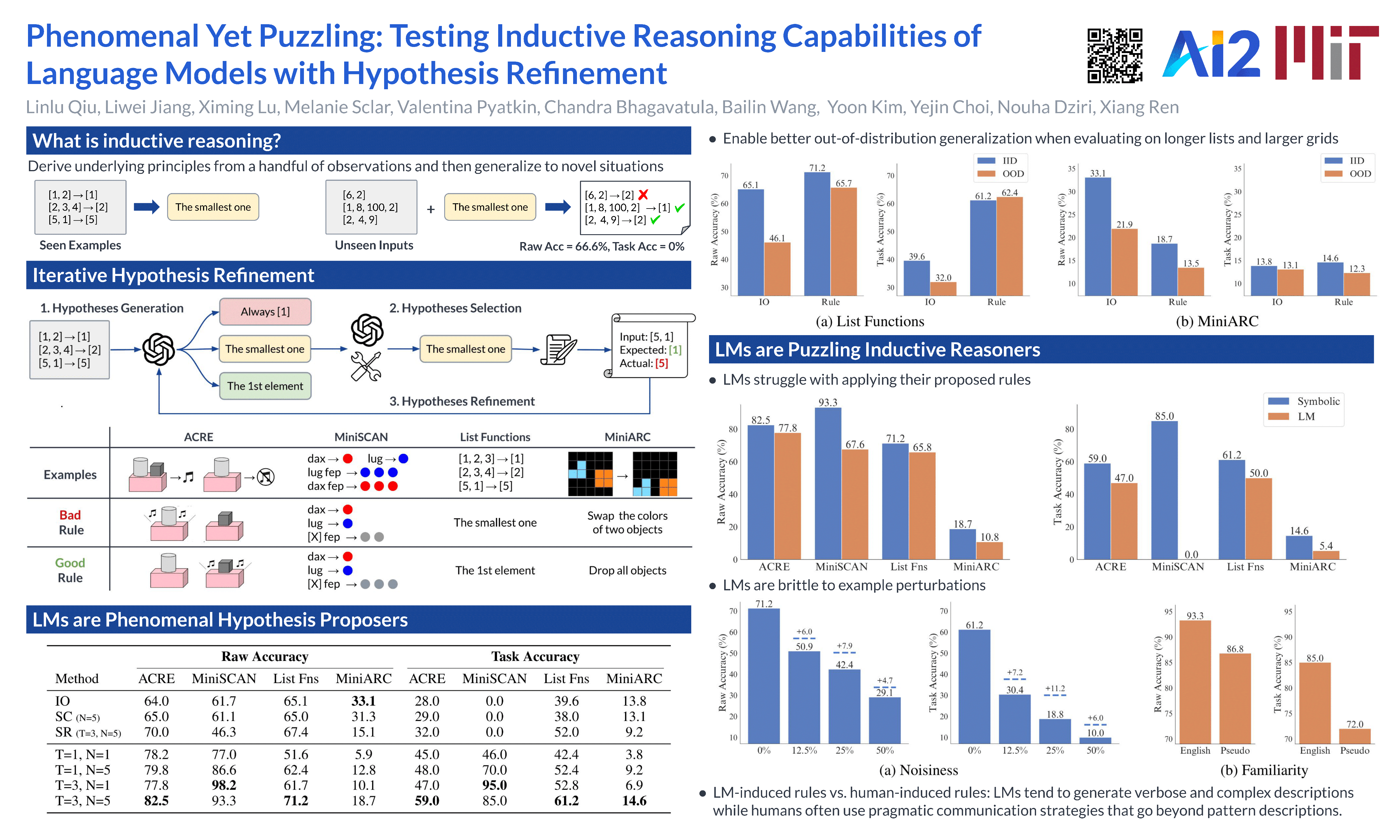
The ability to derive underlying principles from a handful of observations and then generalize to novel situations---known as inductive reasoning---is central to human intelligence. Prior work suggests that language models (LMs) often fall short on inductive reasoning, despite achieving impressive success on research benchmarks. In this work, we conduct a systematic study of the inductive reasoning capabilities of LMs through $\textit{iterative hypothesis refinement}$, a technique that more closely mirrors the human inductive process than standard input-output prompting. Iterative hypothesis refinement employs a three-step process: proposing, selecting, and refining hypotheses in the form of textual rules. By examining the intermediate rules, we observe that LMs are phenomenal $\textit{hypothesis proposers}$ (i.e., generating candidate rules), and when coupled with a (task-specific) symbolic interpreter that is able to systematically filter the proposed set of rules, this hybrid approach achieves strong results across inductive reasoning benchmarks that require inducing causal relations, language-like instructions, and symbolic concepts. However, they also behave as puzzling $\textit{inductive reasoners}$, showing notable performance gaps between rule induction (i.e., identifying plausible rules) and rule application (i.e., applying proposed rules to instances), suggesting that LMs are proposing hypotheses without being able to actually apply the rules. Through empirical and human analyses, we further reveal several discrepancies between the inductive reasoning processes of LMs and humans, shedding light on both the potentials and limitations of using LMs in inductive reasoning tasks.
Video
Chat is not available.
Successful Page Load