Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning
{kind=link}
Abstract
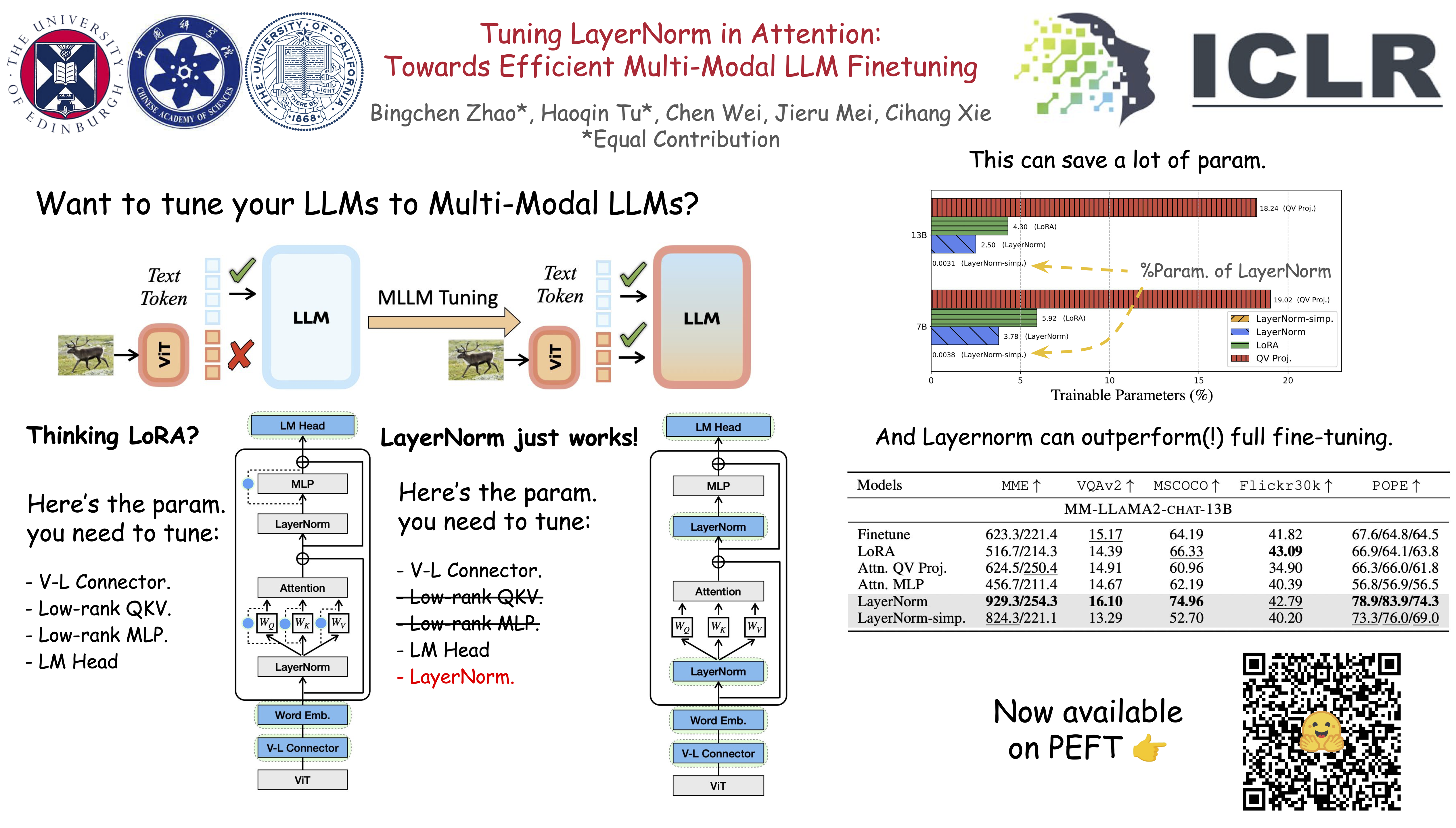
This paper introduces an efficient strategy to transform Large Language Models (LLMs) into Multi-Modal Large Language Models. By conceptualizing this transformation as a domain adaptation process, \ie, transitioning from text understanding to embracing multiple modalities, we intriguingly note that, within each attention block, tuning LayerNorm suffices to yield strong performance. Moreover, when benchmarked against other tuning approaches like full parameter finetuning or LoRA, its benefits on efficiency are substantial.For example, when compared to LoRA on a 13B model scale, performance can be enhanced by an average of over 20\% across five multi-modal tasks, and meanwhile, results in a significant reduction of trainable parameters by 41.9\% and a decrease in GPU memory usage by 17.6\%. On top of this LayerNorm strategy, we showcase that selectively tuning only with conversational data can improve efficiency further. Beyond these empirical outcomes, we provide a comprehensive analysis to explore the role of LayerNorm in adapting LLMs to the multi-modal domain and improving the expressive power of the model.