Theoretical Understanding of Learning from Adversarial Perturbations
{kind=link}
Abstract
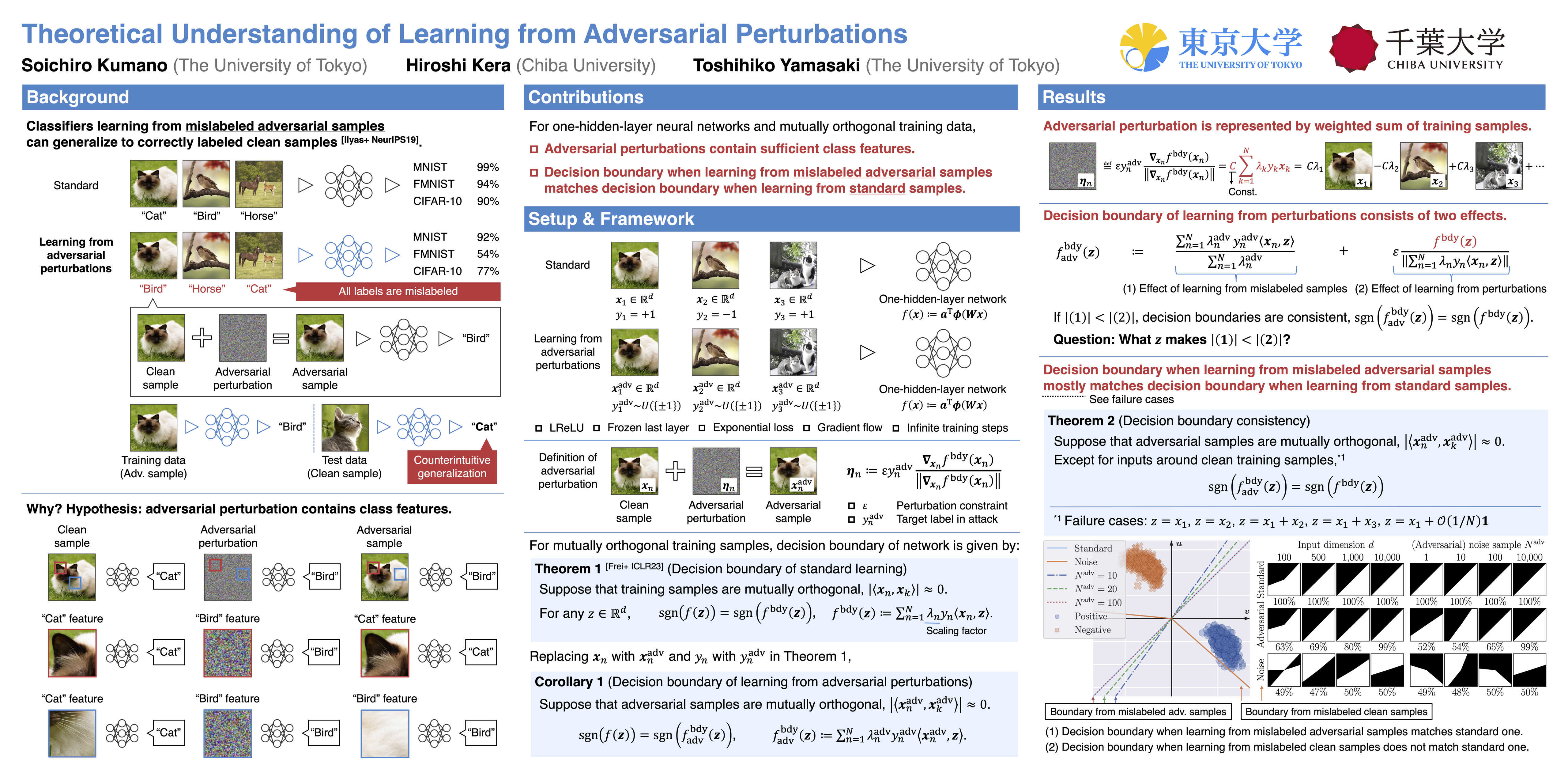
It is not fully understood why adversarial examples can deceive neural networks and transfer between different networks. To elucidate this, several studies have hypothesized that adversarial perturbations, while appearing as noises, contain class features. This is supported by empirical evidence showing that networks trained on mislabeled adversarial examples can still generalize well to correctly labeled test samples. However, a theoretical understanding of how perturbations include class features and contribute to generalization is limited. In this study, we provide a theoretical framework for understanding learning from perturbations using a one-hidden-layer network trained on mutually orthogonal samples. Our results highlight that various adversarial perturbations, even perturbations of a few pixels, contain sufficient class features for generalization. Moreover, we reveal that the decision boundary when learning from perturbations matches that from standard samples except for specific regions under mild conditions. The code is available at https://github.com/s-kumano/learning-from-adversarial-perturbations.