CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
{kind=link}
Abstract
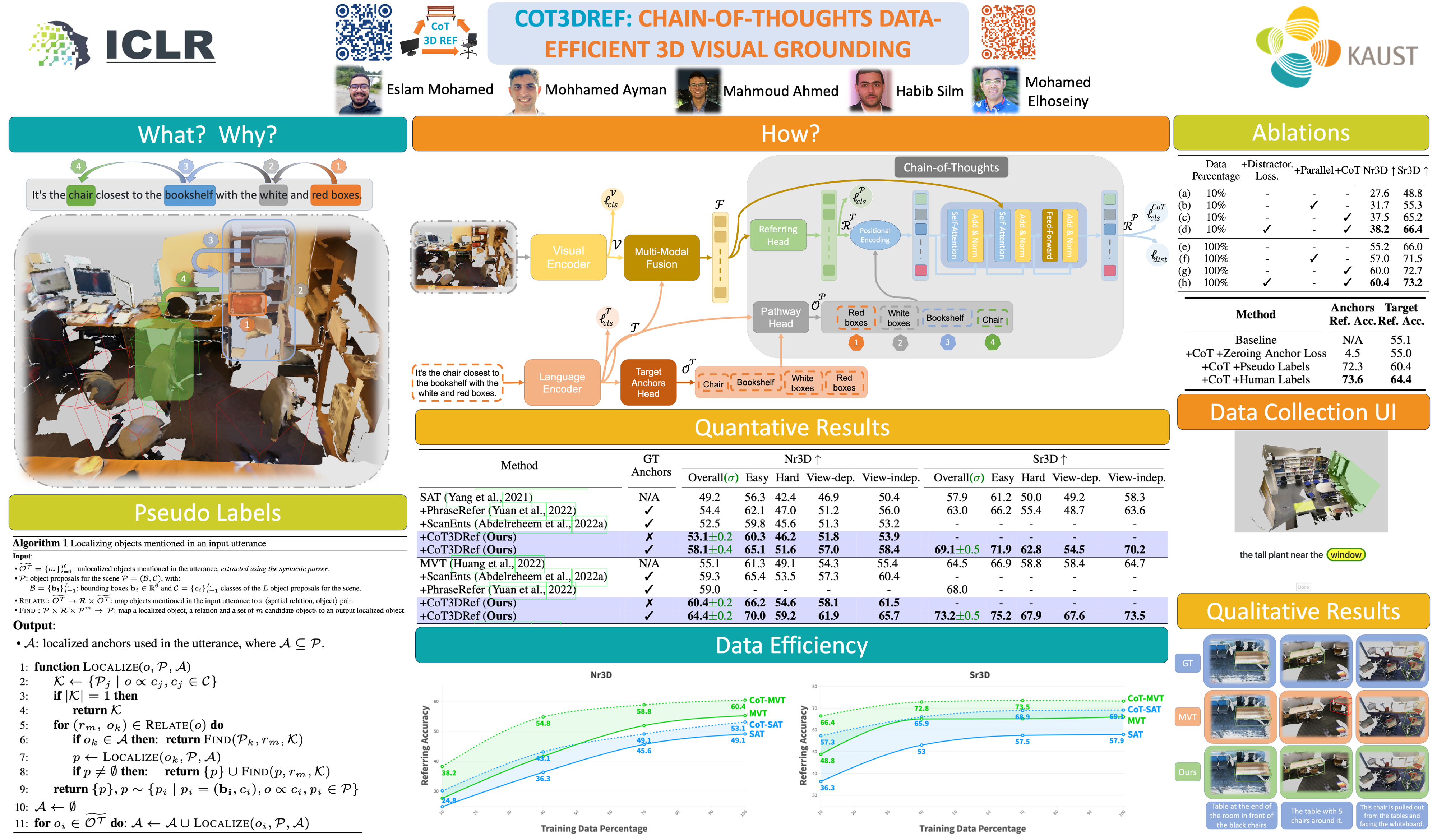
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question “Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?”. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence (Seq2Seq) task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data. The code is available at github.com/eslambakr/CoT 3DV G.