GIM: Learning Generalizable Image Matcher From Internet Videos
{kind=link}
Abstract
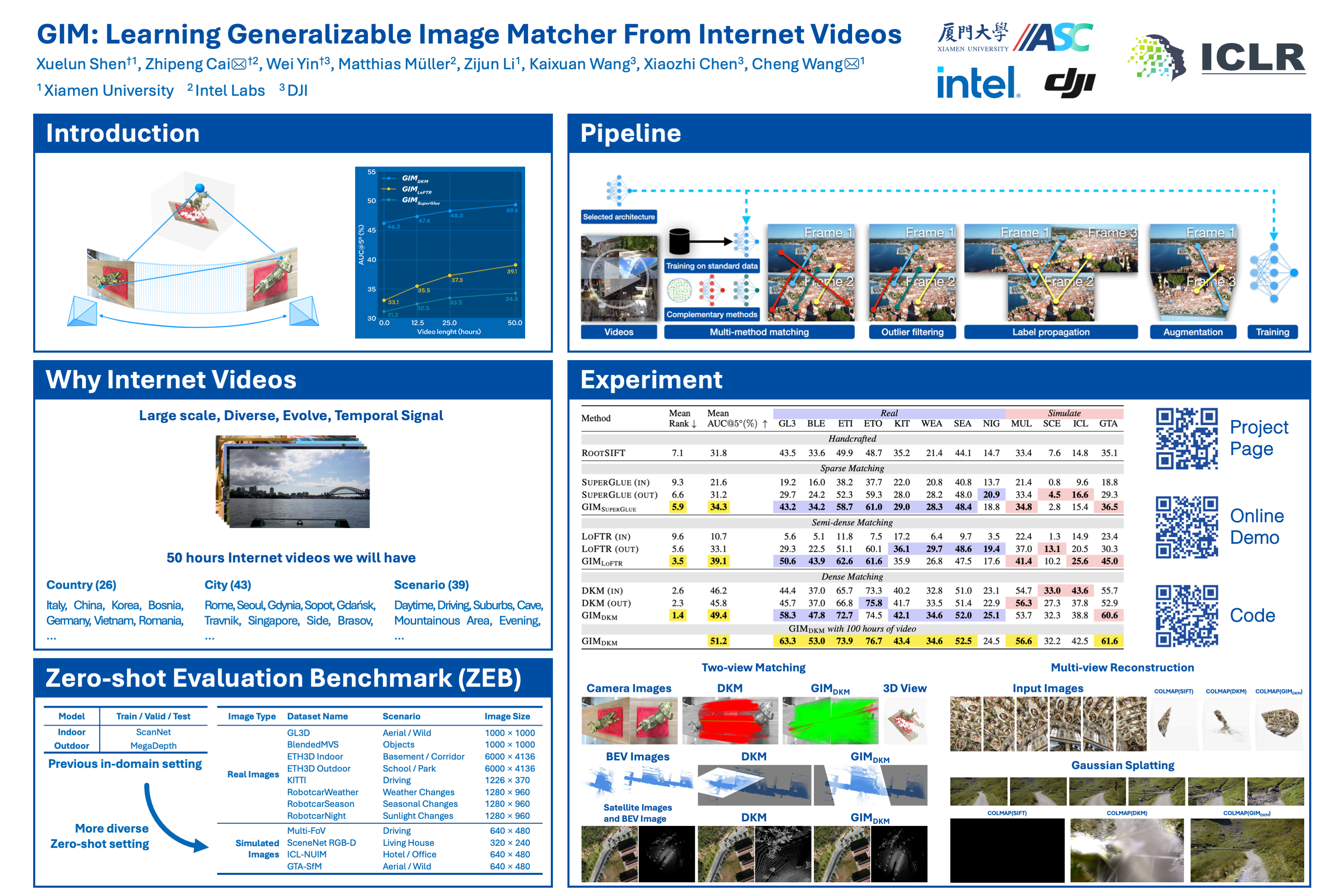
Image matching is a fundamental computer vision problem. While learning-based methods achieve state-of-the-art performance on existing benchmarks, they generalize poorly to in-the-wild images. Such methods typically need to train separate models for different scene types (e.g., indoor vs. outdoor) and are impractical when the scene type is unknown in advance. One of the underlying problems is the limited scalability of existing data construction pipelines, which limits the diversity of standard image matching datasets. To address this problem, we propose GIM, a self-training framework for learning a single generalizable model based on any image matching architecture using internet videos, an abundant and diverse data source. Given an architecture, GIM first trains it on standard domain-specific datasets and then combines it with complementary matching methods to create dense labels on nearby frames of novel videos. These labels are filtered by robust fitting, and then enhanced by propagating them to distant frames. The final model is trained on propagated data with strong augmentations. Not relying on complex 3D reconstruction makes GIM much more efficient and less likely to fail than standard SfM-and-MVS based frameworks. We also propose ZEB, the first zero-shot evaluation benchmark for image matching. By mixing data from diverse domains, ZEB can thoroughly assess the cross-domain generalization performance of different methods. Experiments demonstrate the effectiveness and generality of GIM. Applying GIM consistently improves the zero-shot performance of 3 state-of-the-art image matching architectures as the number of downloaded videos increases (Fig. 1 (a)); with 50 hours of YouTube videos, the relative zero-shot performance improves by 6.9% − 18.1%. GIM also enables generalization to extreme cross-domain data such as Bird Eye View (BEV) images of projected 3D point clouds (Fig. 1 (c)). More importantly, our single zero-shot model consistently outperforms domain-specific baselines when evaluated on downstream tasks inherent to their respective domains. The code will be released upon acceptance.