Scaling Laws of RoPE-based Extrapolation
Xiaoran Liu ⋅ Hang Yan ⋅ Chenxin An ⋅ Xipeng Qiu ⋅ Dahua Lin
2024 Poster
{kind=link}
Abstract
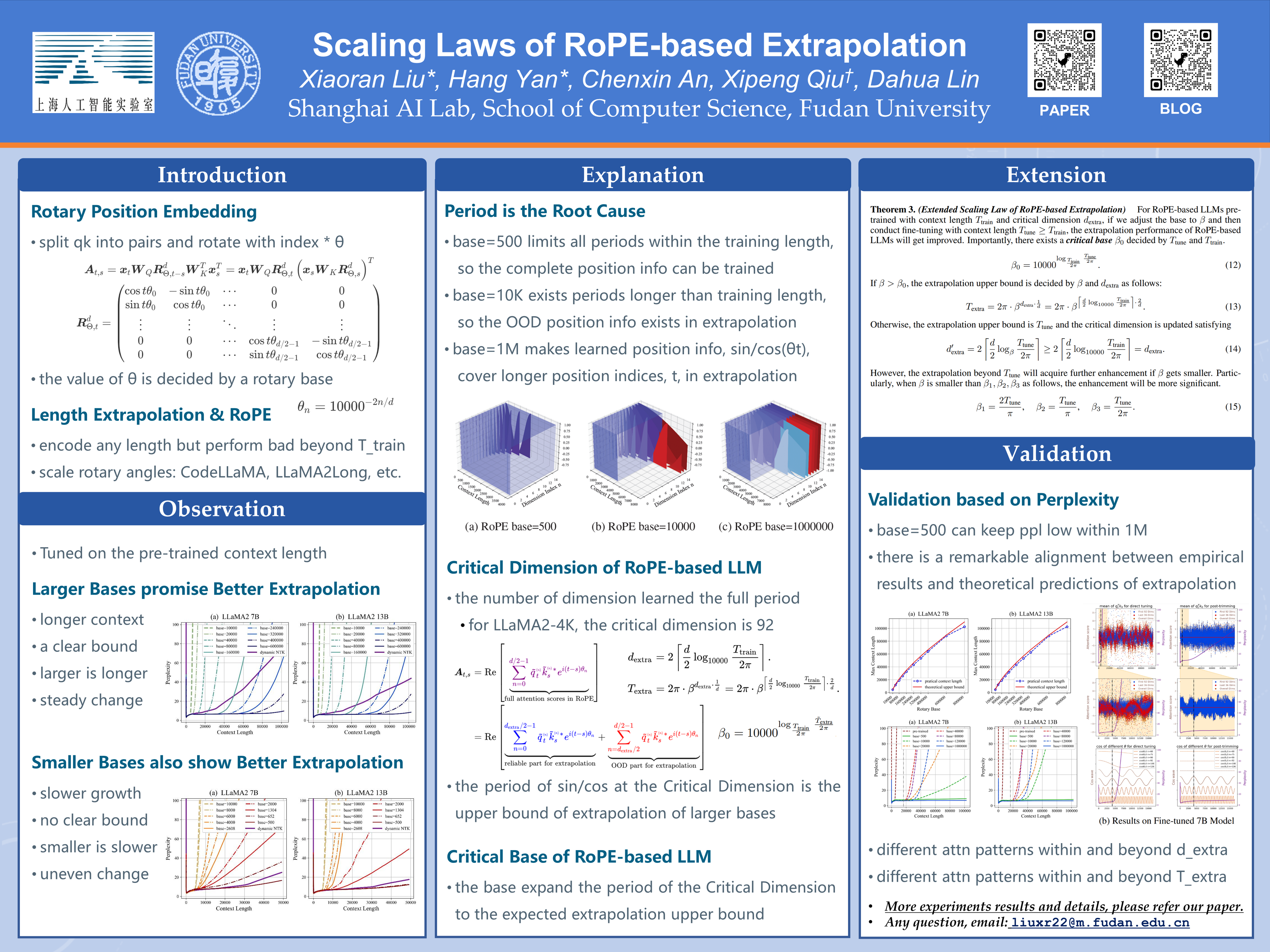
The extrapolation capability of Large Language Models (LLMs) based on Rotary Position Embedding \citep{su2021roformer} is currently a topic of considerable interest. The mainstream approach to addressing extrapolation with LLMs involves modifying RoPE by replacing 10000, the rotary base of $\theta_n={10000}^{-2n/d}$ in the original RoPE, with a larger value and providing longer fine-tuning text. In this work, we first observe that fine-tuning a RoPE-based LLM with either a smaller or larger base in pre-training context length could significantly enhance its extrapolation performance. After that, we propose \textbf{\textit{Scaling Laws of RoPE-based Extrapolation}}, a unified framework from the periodic perspective, to describe the relationship between the extrapolation performance and base value as well as tuning context length. In this process, we also explain the origin of the RoPE-based extrapolation issue by \textbf{\textit{critical dimension for extrapolation}}. Besides these observations and analyses, we achieve extrapolation up to 1 million context length within only 16K training length on LLaMA2 7B and 13B \citep{touvron2023llama2}.
Video
Chat is not available.
Successful Page Load