ZeroFlow: Scalable Scene Flow via Distillation
Kyle Vedder ⋅ Neehar Peri ⋅ Nathaniel Chodosh ⋅ Ishan Khatri ⋅ ERIC EATON ⋅ Dinesh Jayaraman ⋅ Yang Liu ⋅ Deva Ramanan ⋅ James Hays
2024 Poster
{kind=link}
Abstract
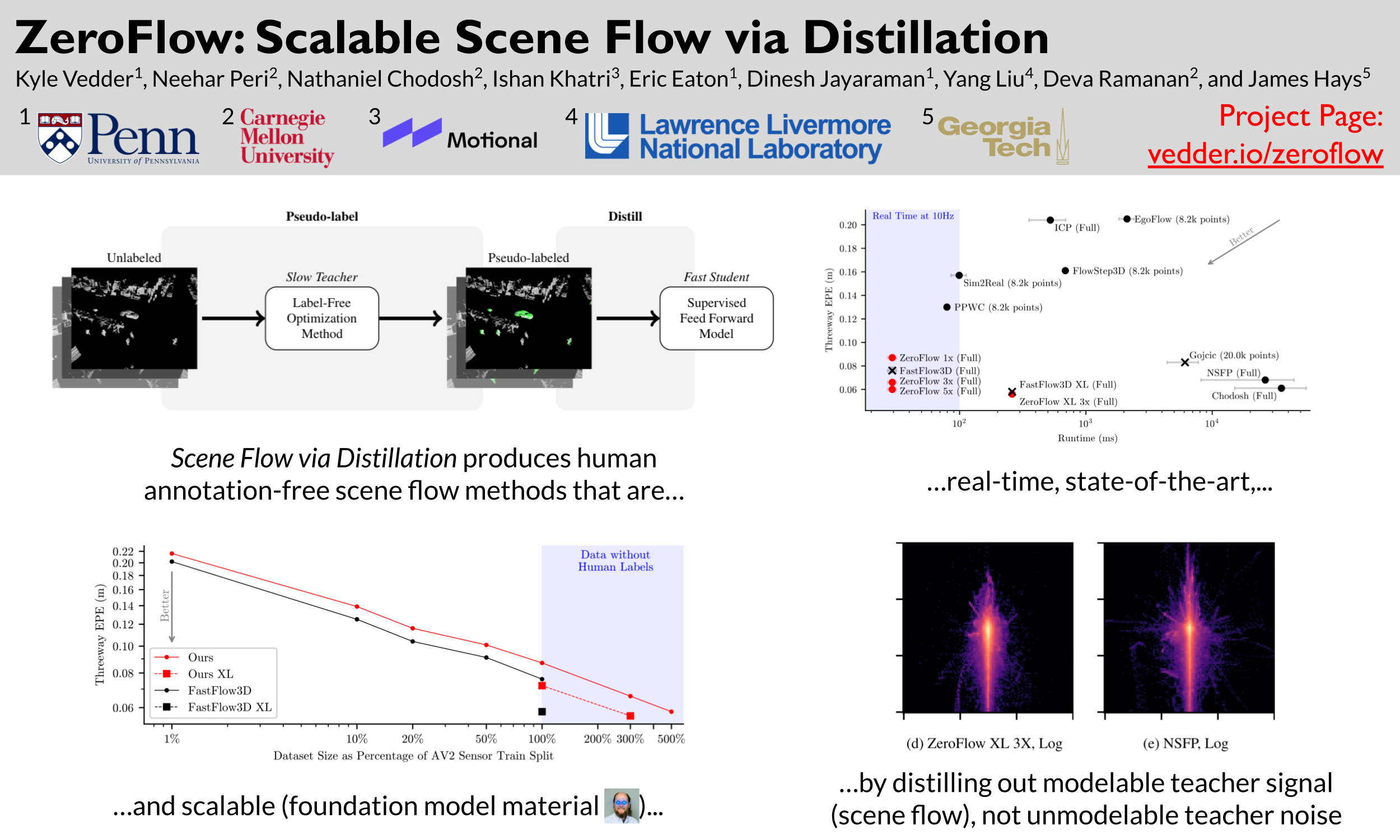
Scene flow estimation is the task of describing the 3D motion field between temporally successive point clouds. State-of-the-art methods use strong priors and test-time optimization techniques, but require on the order of tens of seconds to process full-size point clouds, making them unusable as computer vision primitives for real-time applications such as open world object detection. Feedforward methods are considerably faster, running on the order of tens to hundreds of milliseconds for full-size point clouds, but require expensive human supervision. To address both limitations, we propose _Scene Flow via Distillation_, a simple, scalable distillation framework that uses a label-free optimization method to produce pseudo-labels to supervise a feedforward model. Our instantiation of this framework, _ZeroFlow_, achieves **state-of-the-art** performance on the _Argoverse 2 Self-Supervised Scene Flow Challenge_ while using zero human labels by simply training on large-scale, diverse unlabeled data. At test-time, ZeroFlow is over 1000$\times$ faster than label-free state-of-the-art optimization-based methods on full-size point clouds (34 FPS vs 0.028 FPS) and over 1000$\times$ cheaper to train on unlabeled data compared to the cost of human annotation (\\$394 vs ~\\$750,000). To facilitate further research, we will release our code, trained model weights, and high quality pseudo-labels for the Argoverse 2 and Waymo Open datasets.
Video
Chat is not available.
Successful Page Load