HyperAttention: Long-context Attention in Near-Linear Time
{kind=link}
Abstract
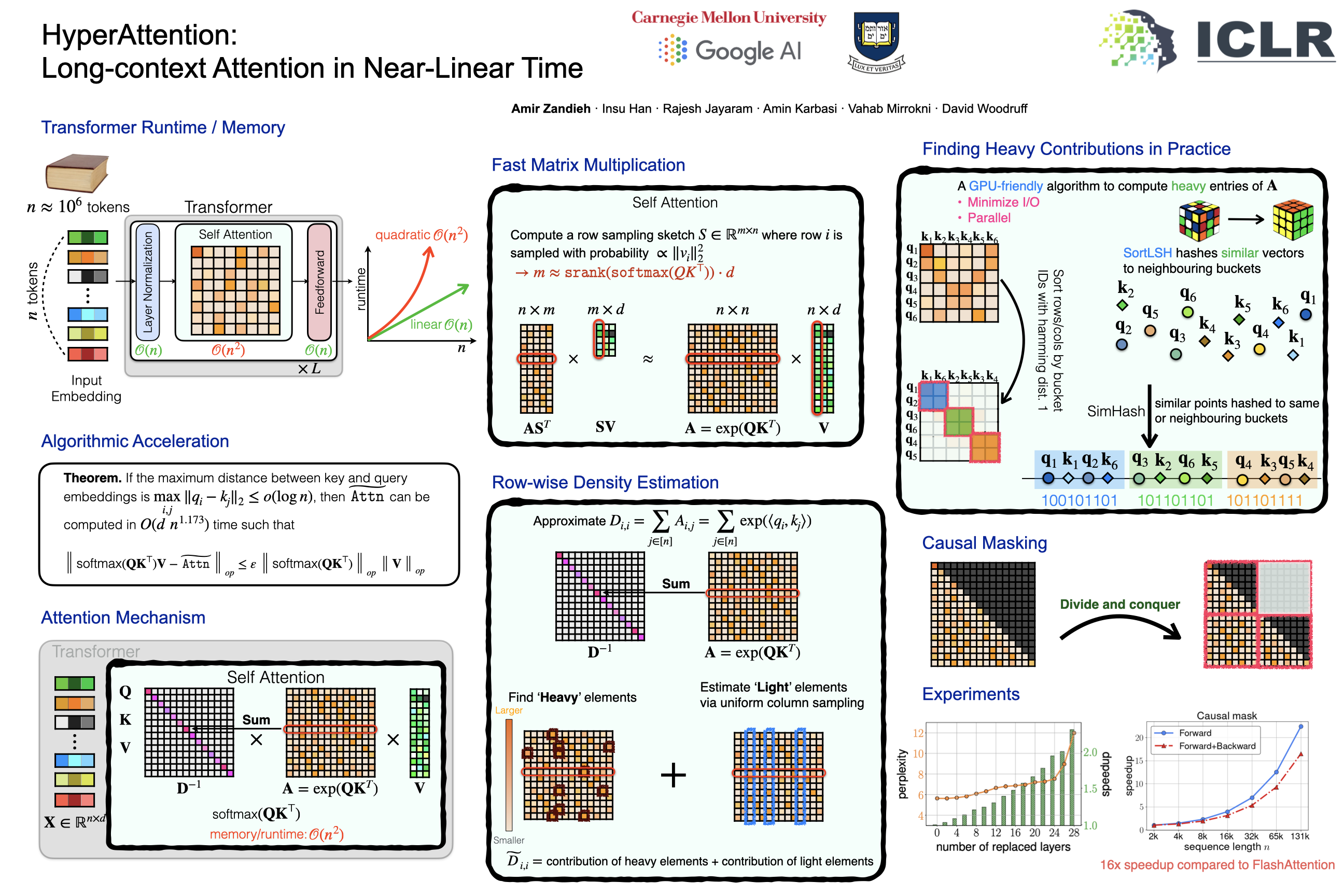
We present an approximate attention mechanism named HyperAttention to address the computational challenges posed by the growing complexity of long contexts used in Large Language Models (LLMs). Recent work suggests that in the worst-case scenario, the quadratic time is necessary unless the entries of the attention matrix are bounded or the matrix has low stable rank. We introduce two parameters which measure: (1) the max column norm in the normalized attention matrix, and (2) the ratio of row norms in the unnormalized attention matrix after detecting and removing large entries. We use these fine-grained parameters to capture the hardness of the problem. Despite previous lower bounds, we are able to achieve a linear time sampling algorithm even when the matrix has unbounded entries or a large stable rank, provided the above parameters are small.HyperAttention features a modular design that easily accommodates integration of other fast low-level implementations, particularly FlashAttention. Empirically, employing Locality Sensitive Hashing (LSH) to identify large entries, HyperAttention outperforms existing methods, giving significant speed improvements compared to state-of-the-art solutions like FlashAttention. This development presents substantial implications for enabling LLMs to handle significantly larger contexts.