CellPLM: Pre-training of Cell Language Model Beyond Single Cells
Hongzhi Wen ⋅ Wenzhuo Tang ⋅ Xinnan Dai ⋅ Jiayuan Ding ⋅ Wei Jin ⋅ Yuying Xie ⋅ Jiliang Tang
2024 Poster
{kind=link}
Abstract
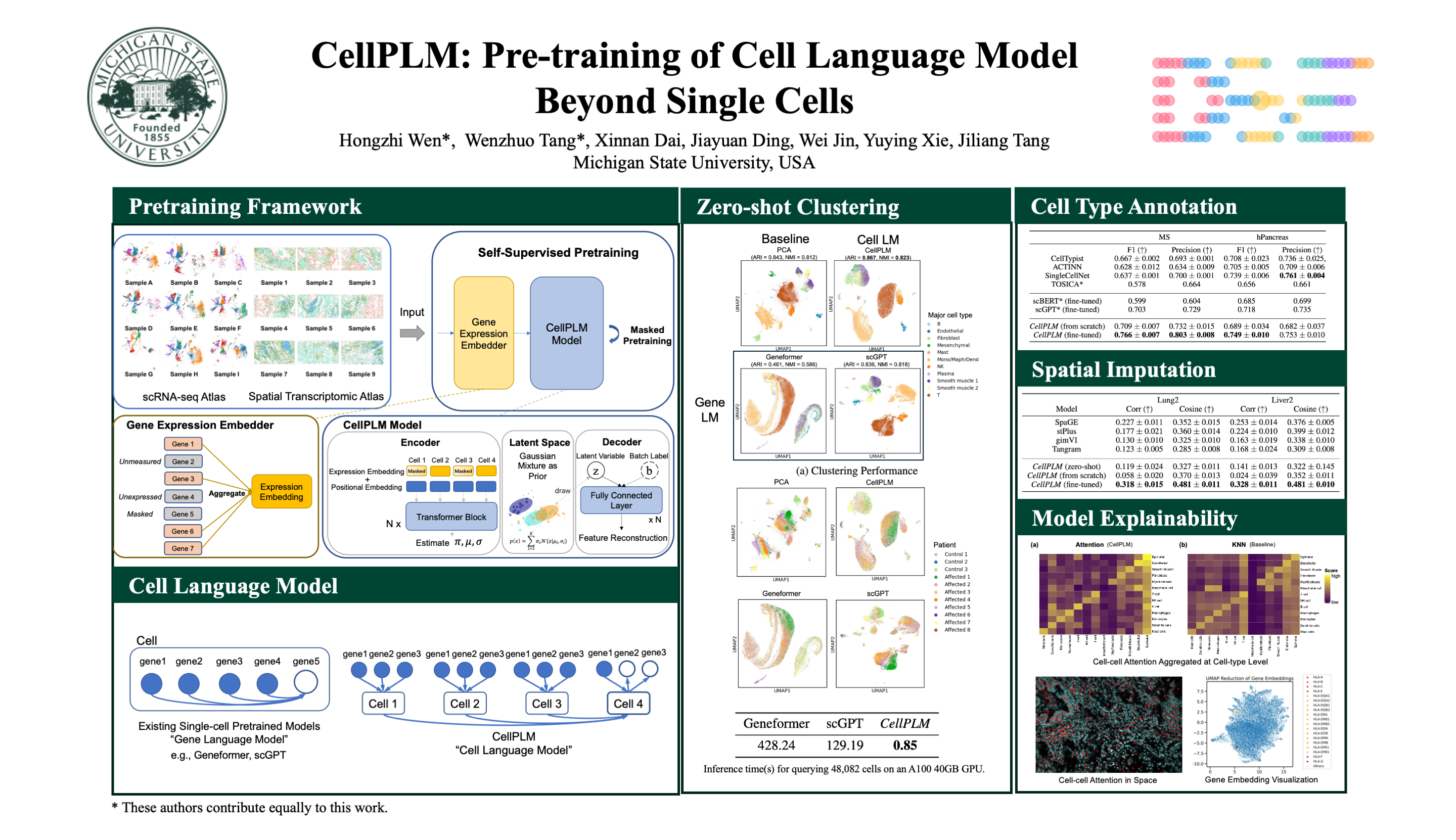
The current state-of-the-art single-cell pre-trained models are greatly inspired by the success of large language models. They trained transformers by treating genes as tokens and cells as sentences. However, three fundamental differences between single-cell data and natural language data are overlooked: (1) scRNA-seq data are presented as bag-of-genes instead of sequences of RNAs; (2) Cell-cell relations are more intricate and important than inter-sentence relations; and (3) The quantity of single-cell data is considerably inferior to text data, and they are very noisy. In light of these characteristics, we propose a new pre-trained model, $\textit{CellPLM}$, which takes cells as tokens and tissues as sentences. In addition, we leverage spatially-resolved transcriptomic data in pre-training to facilitate learning cell-cell relationships and introduce a Gaussian prior distribution as an additional inductive bias to overcome data limitations. $\textit{CellPLM}$ is the first single-cell pre-trained transformer that encodes cell-cell relations and it consistently outperforms existing pre-trained and non-pre-trained models in diverse downstream tasks, with 100 times higher inference speed on generating cell embeddings than previous pre-trained models.
Video
Chat is not available.
Successful Page Load