Understanding Augmentation-based Self-Supervised Representation Learning via RKHS Approximation and Regression
{kind=link}
Abstract
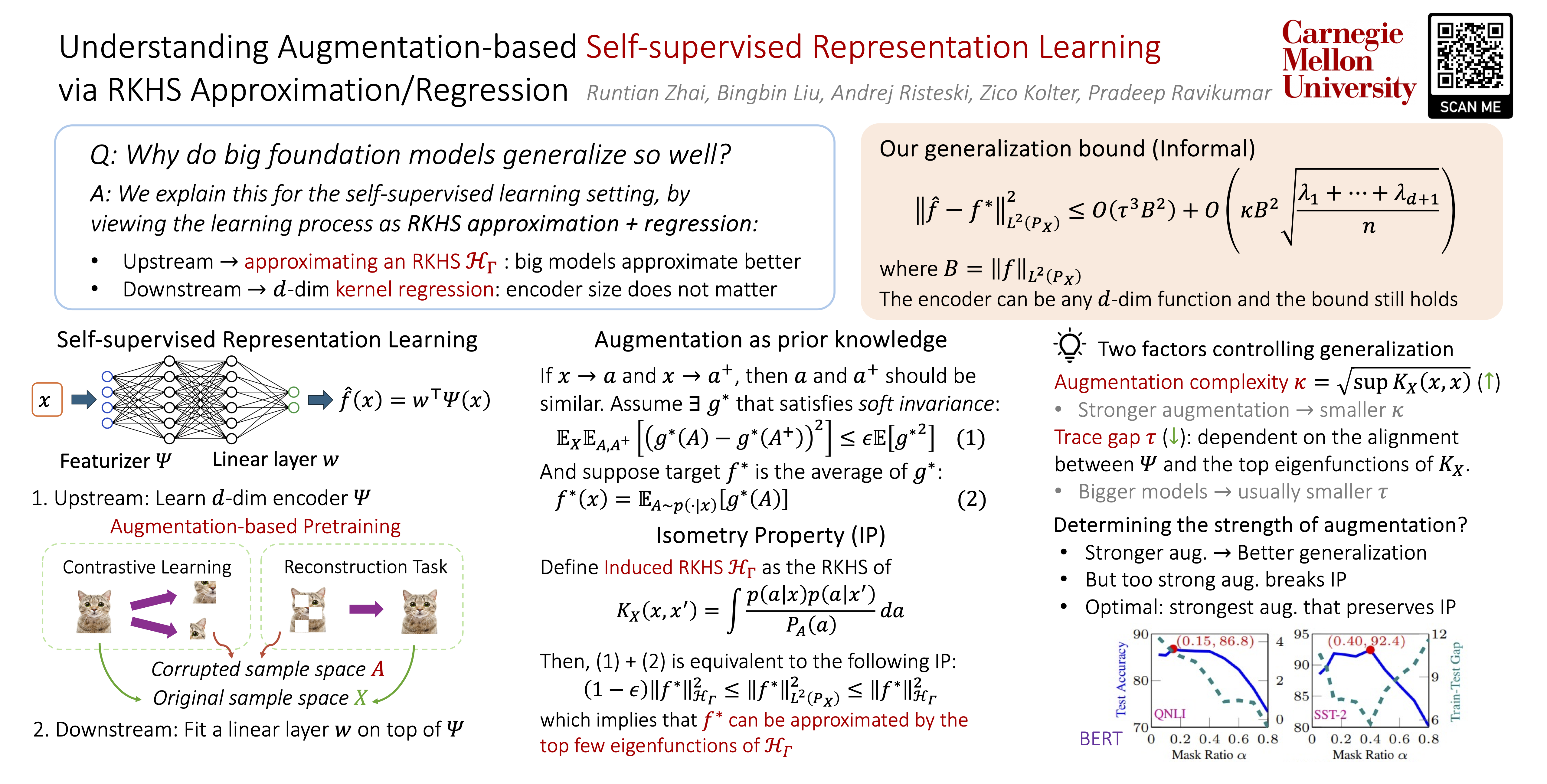
Data augmentation is critical to the empirical success of modern self-supervised representation learning, such as contrastive learning and masked language modeling.However, a theoretical understanding of the exact role of the augmentation remains limited.Recent work has built the connection between self-supervised learning and the approximation of the top eigenspace of a graph Laplacian operator, suggesting that learning a linear probe atop such representation can be connected to RKHS regression.Building on this insight, this work delves into a statistical analysis of augmentation-based pretraining.Starting from the isometry property, a geometric characterization of the target function given by the augmentation, we disentangle the effects of the model and the augmentation,and prove two generalization bounds that are free of model complexity.Our first bound works for an arbitrary encoder, and it is the sum of an estimation error bound incurred by fitting a linear probe, and an approximation error bound by RKHS approximation.Our second bound specifically addresses the casewhere the encoder extracts the top-d eigenspace of a finite-sample-based approximation of the underlying RKHS.A key ingredient in our analysis is the augmentation complexity,which we use to quantitatively compare different augmentations and analyze their impact on downstream performance.