Learning with a Mole: Transferable latent spatial representations for navigation without reconstruction
{kind=link}
Abstract
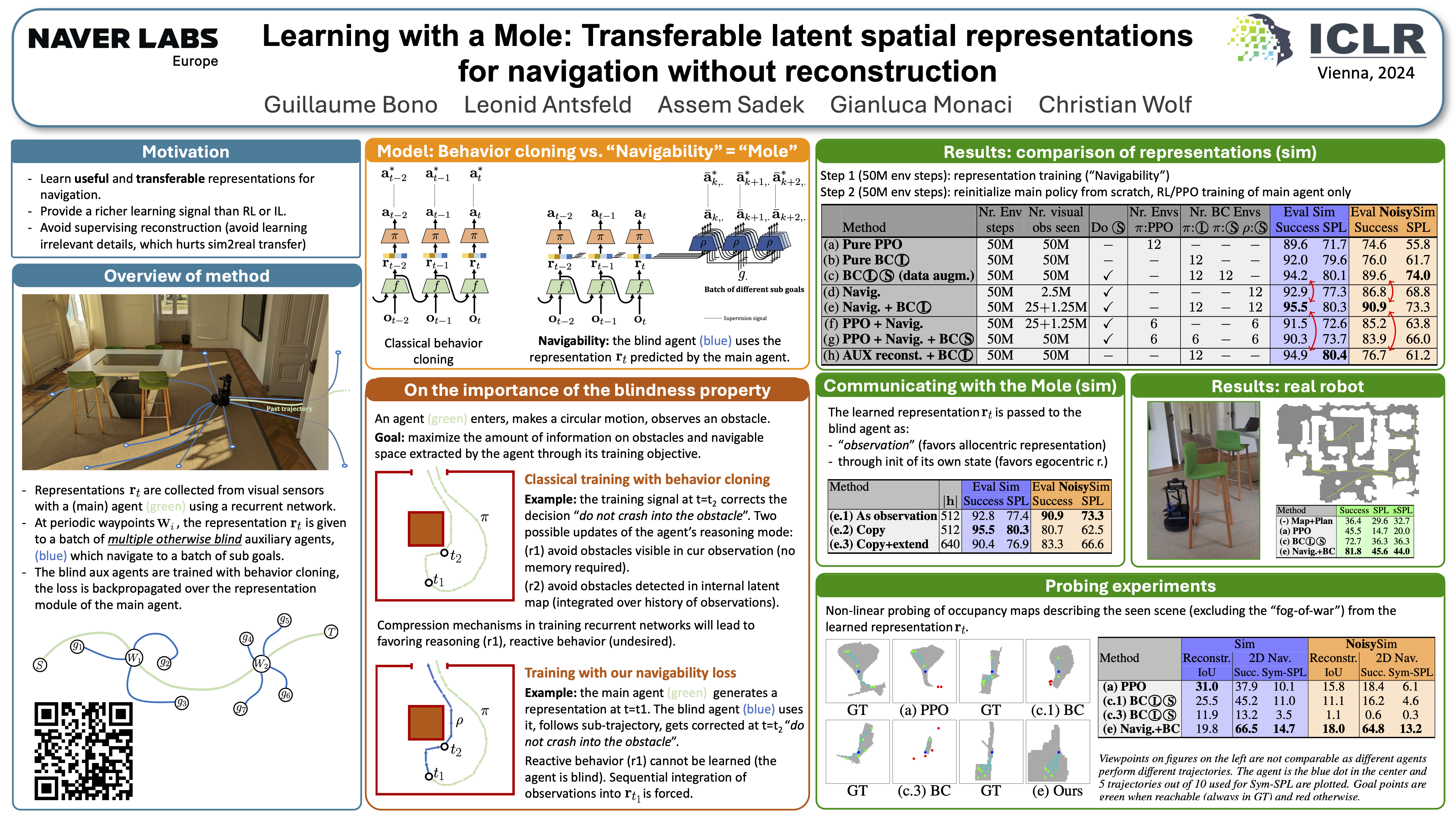
Agents navigating in 3D environments require some form of memory, which should hold a compact and actionable representation of the history of observations useful for decision taking and planning. In most end-to-end learning approaches the representation is latent and usually does not have a clearly defined interpretation, whereas classical robotics addresses this with scene reconstruction resulting in some form of map, usually estimated with geometry and sensor models and/or learning. In this work we propose to learn an actionable representation of the scene independently of the targeted downstream task and without explicitly optimizing reconstruction. The learned representation is optimized by a blind auxiliary agent trained to navigate with it on multiple short sub episodes branching out from a waypoint and, most importantly, without any direct visual observation. We argue and show that the blindness property is important and forces the (trained) latent representation to be the only means for planning. With probing experiments we show that the learned representation optimizes navigability and not reconstruction. On downstream tasks we show that it is robust to changes in distribution, in particular the sim2real gap, which we evaluate with a real physical robot in a real office building, significantly improving performance.