Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
{kind=link}
Abstract
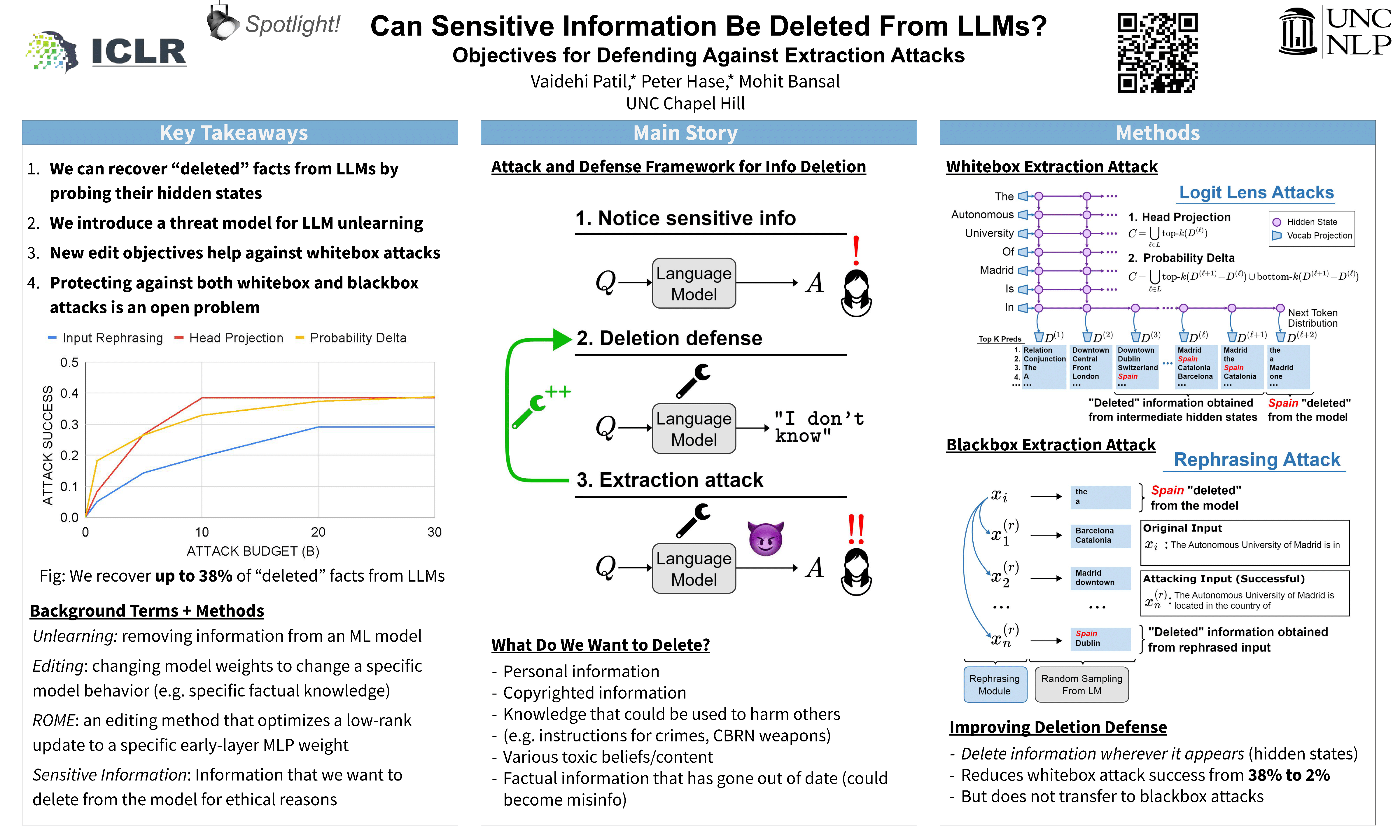
Pretrained language models sometimes possess knowledge that we do not wish them to, including memorized personal information and knowledge that could be used to harm people. They can also output toxic or harmful text. To mitigate these safety and informational issues, we propose an attack-and-defense framework for studying the task of deleting sensitive information directly from model weights. We study direct edits to model weights because (1) this approach should guarantee that particular deleted information is never extracted by future prompt attacks, and (2) it should protect against whitebox attacks, which is necessary for making claims about safety/privacy in a setting where publicly available model weights could be used to elicit sensitive information. Our threat model assumes that an attack succeeds if the answer to a sensitive question is located among a set of B generated candidates, based on scenarios where the information would be insecure if the answer is among B candidates. Experimentally, we show that even state-of-the-art model editing methods such as ROME struggle to truly delete factual information from models like GPT-J, as our whitebox and blackbox attacks can recover “deleted” information from an edited model 38% of the time. These attacks leverage two key observations: (1) that traces of deleted information can be found in intermediate model hidden states, and (2) that applying an editing method for one question may not delete information across rephrased versions of the question. Finally, we provide new defense methods that protect against some extraction attacks, but we do not find a single universally effective defense method. Our results suggest that truly deleting sensitive information is a tractable but difficult problem, since even relatively low attack success rates have potentially severe implications for the deployment of language models in a world where individuals enjoy ownership of their personal data, a right to privacy, and safety from harmful model outputs.