Efficient-3Dim: Learning a Generalizable Single-image Novel-view Synthesizer in One Day
{kind=link}
Abstract
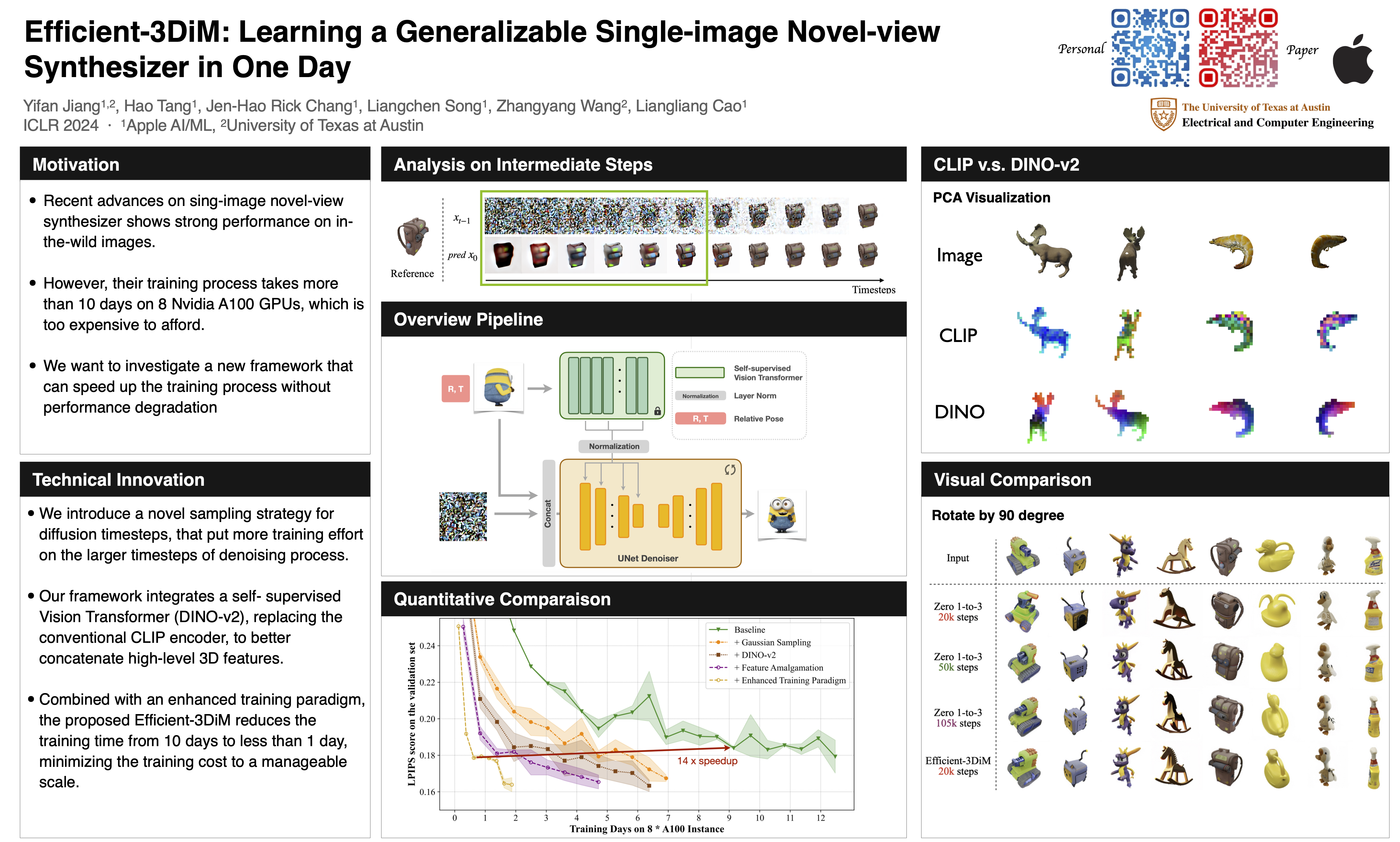
The task of novel view synthesis aims to generate unseen perspectives of an object or scene from a limited set of input images. Nevertheless, synthesizing novel views from a single image remains a significant challenge. Previous approaches tackle this problem by adopting mesh prediction, multi-plane image construction, or more advanced techniques such as neural radiance fields. Recently, a pre-trained diffusion model that is specifically designed for 2D image synthesis has demonstrated its capability in producing photorealistic novel views, if sufficiently optimized with a 3D finetuning task. Despite greatly improved fidelity and generalizability, training such a powerful diffusion model requires a vast volume of training data and model parameters, resulting in a notoriously long time and high computational costs. To tackle this issue, we propose Efficient-3DiM, a highly efficient yet effective framework to learn a single-image novel-view synthesizer. Motivated by our in-depth analysis of the diffusion model inference process, we propose several pragmatic strategies to reduce training overhead to a manageable scale, including a crafted timestep sampling strategy, a superior 3D feature extractor, and an enhanced training scheme. When combined, our framework can reduce the total training time from 10 days to less than 1 day, significantly accelerating the training process on the same computational platform (an instance with 8 Nvidia A100 GPUs). Comprehensive experiments are conducted to demonstrate the efficiency and generalizability of our proposed method.