NEFTune: Noisy Embeddings Improve Instruction Finetuning
Neel Jain ⋅ Ping-yeh Chiang ⋅ Yuxin Wen ⋅ John Kirchenbauer ⋅ Hong-Min Chu ⋅ Gowthami Somepalli ⋅ Brian Bartoldson ⋅ Bhavya Kailkhura ⋅ Avi Schwarzschild ⋅ Aniruddha Saha ⋅ Micah Goldblum ⋅ Jonas Geiping ⋅ Tom Goldstein
2024 Poster
{kind=link}
Abstract
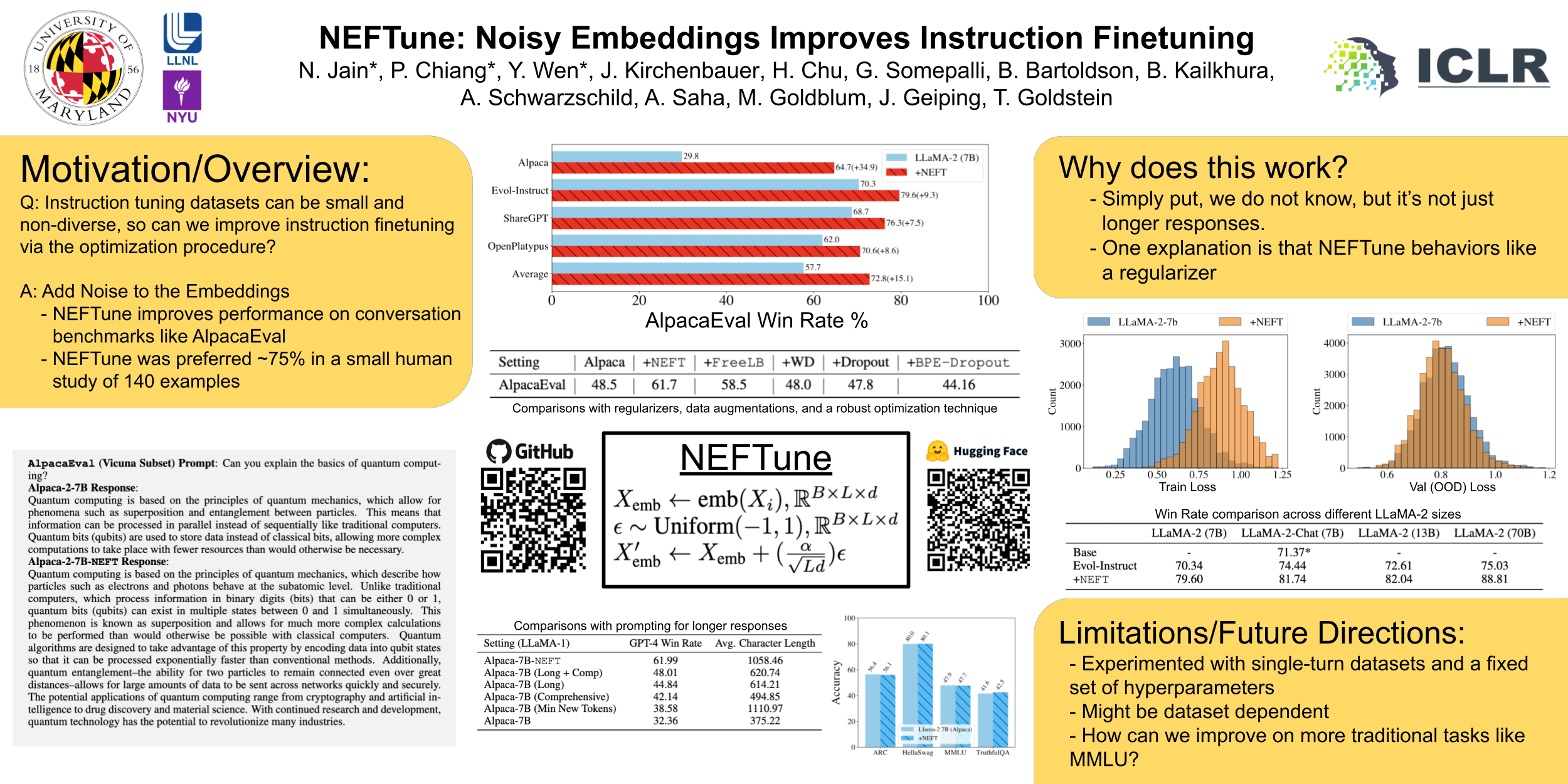
We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training.Standard finetuning of LLaMA-2-7B using Alpaca achieves $29.79$\% on AlpacaEval, which rises to $64.69$\% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets.Models trained with Evol-Instruct see a $10$\% improvement, with ShareGPT an $8$\% improvement, and with OpenPlatypus an $8$\% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune. Particularly, we see these improvements on the conversational abilities of the instruction model and not on traditional tasks like those on the OpenLLM Leaderboard, where performance is the same.
Video
Chat is not available.
Successful Page Load