TF-JEPA: Predictive Alignment of Time–Frequency Representations Without Contrastive Pairs
{kind=link}
Abstract
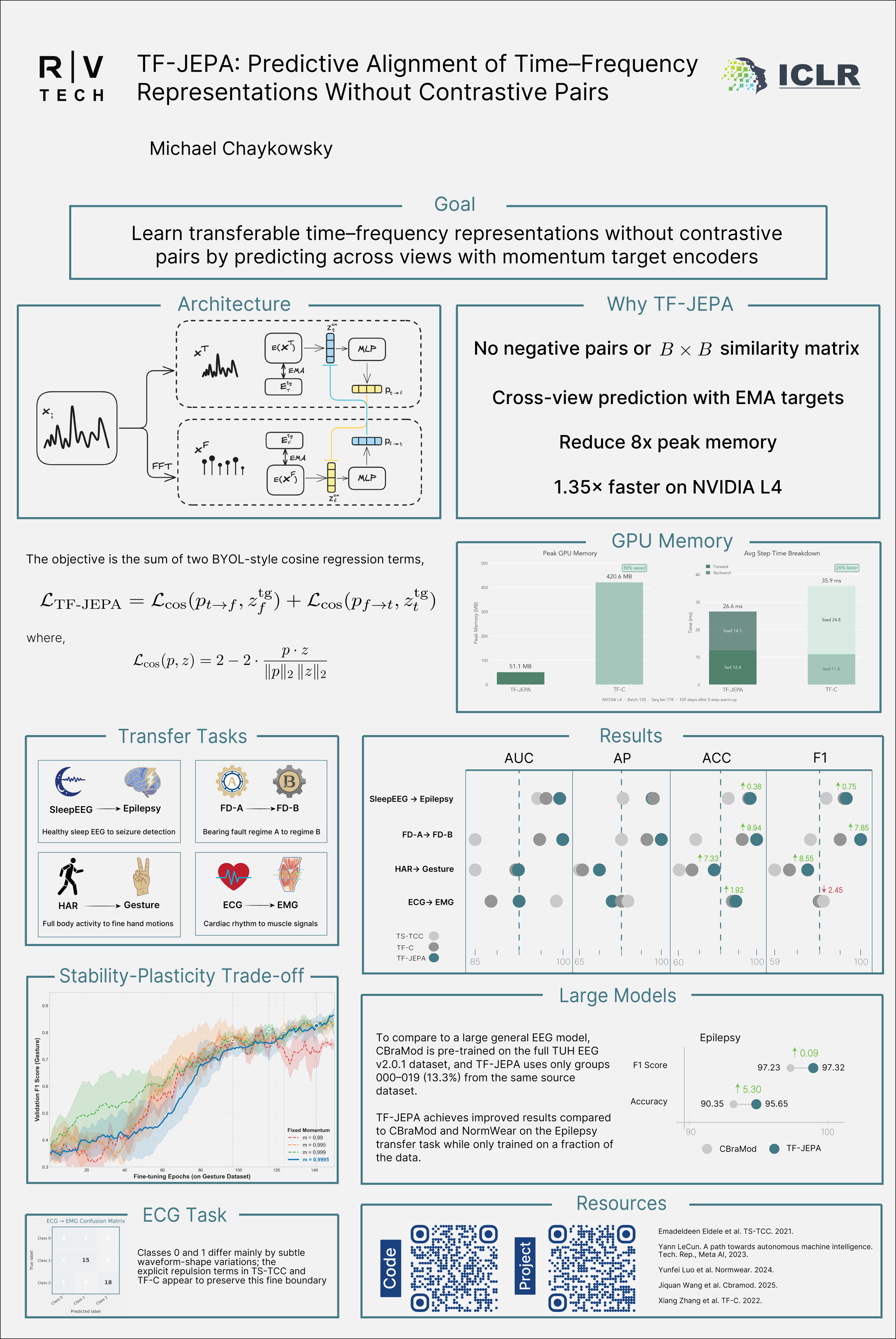
Learning generalizable representations from multivariate time series is challenging due to complex temporal dynamics, distribution shifts, and the difficulty of effectively designing contrastive pairs. We introduce TF-JEPA, a noncontrastive self-supervised method that leverages predictive alignment to integrate representations from the time and frequency domains without relying on negative sampling. TF-JEPA utilizes dual online time and frequency encoders, each paired with its own momentum-updated target encoder, embedding both views into a stable and unified latent space. Experiments on sleep EEG, gesture recognition, mechanical fault detection, and EMG classification demonstrate that TF-JEPA matches or surpasses contrastive and time frequency consistency baselines.