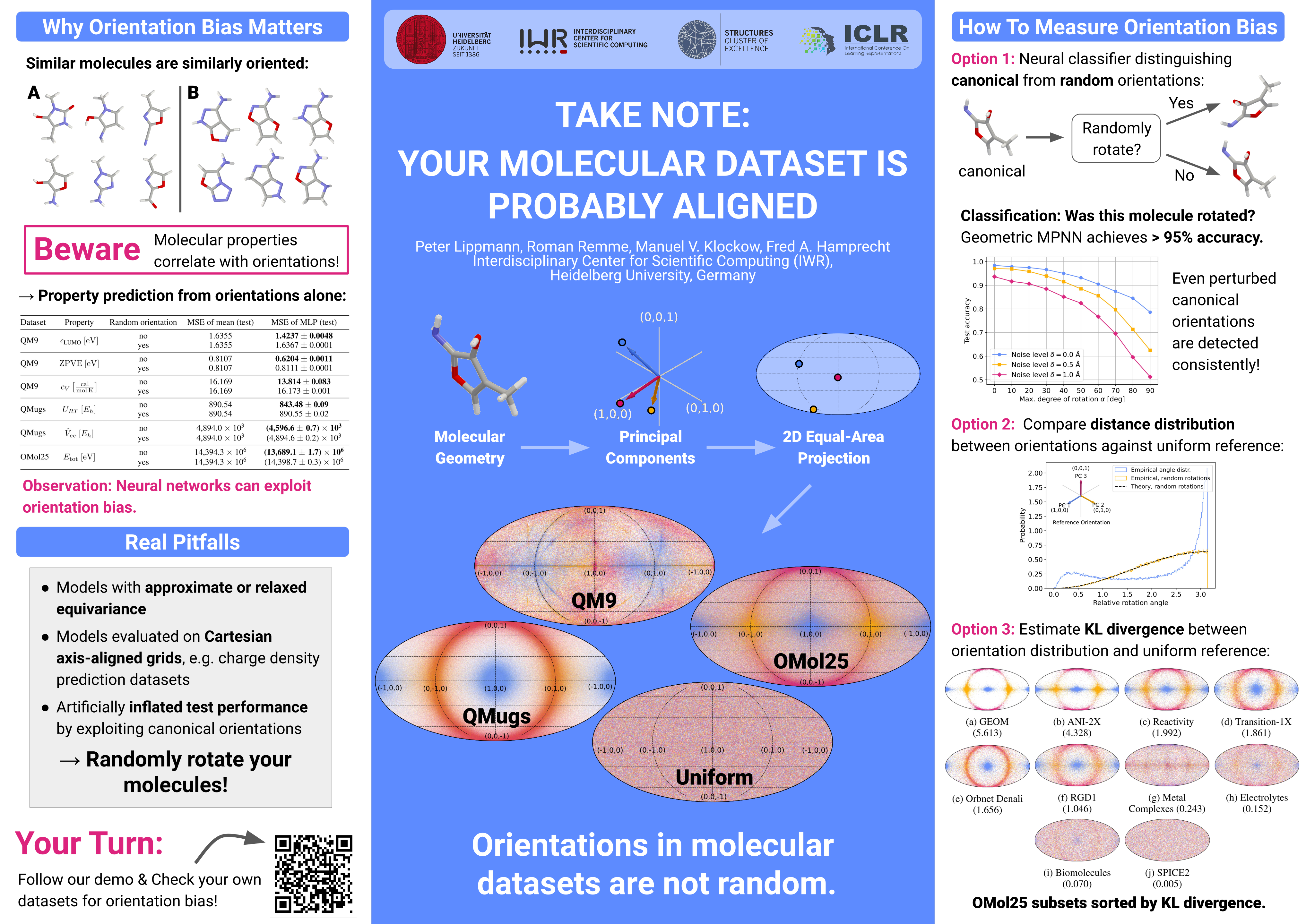
Take Note: Your Molecular Dataset Is Probably Aligned
{kind=link}
Abstract
Massive training datasets are fueling the astounding progress in molecular machine learning. Since these datasets are typically generated with computational chemistry codes which do not randomize pose, the resulting molecular geometries are usually not randomly oriented. While cheminformaticians are well aware of this fact, it can be a real pitfall for machine learners entering the burgeoning field of molecular machine learning. We demonstrate that molecular poses in the popular datasets QM9, QMugs, and OMol25 are indeed biased. While the fact can easily be overlooked by visual inspection alone, we show that a simple classifier can separate original data samples from randomly rotated ones with high accuracy. Second, we empirically validate that neural networks can and do exploit the orientation bias in these datasets by successfully training a model on chemical property prediction using molecular orientation as sole input. Third, we present visualizations of all molecular orientations and confirm that chemically similar molecules tend to have similar canonical poses. In summary, we recall and document orientation bias in the prevalent datasets that machine learners should be aware of.