Local Success Does Not Compose: Benchmarking Large Language Models for Compositional Formal Verification
{kind=link}
Abstract
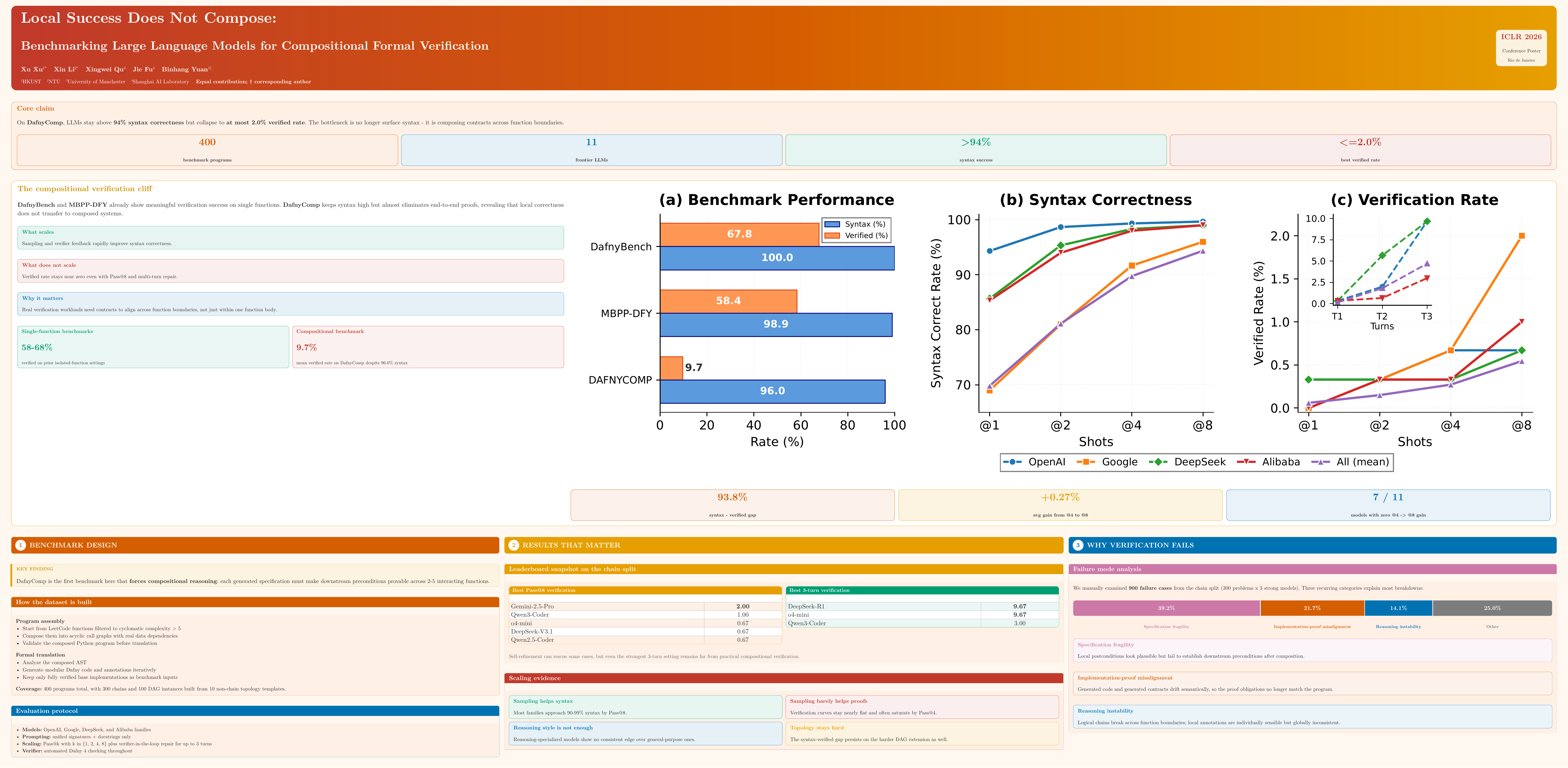
Despite rapid advances in code generation, current Large Language Models (LLMs) still struggle with reliable and verifiable code synthesis in the presence of compositional reasoning requirements across multi-function programs. To study this systematically, we introduce DafnyCOMP, a benchmark for generating compositional Dafny specifications for programs consisting of multiple interacting functions with non-trivial data dependencies. Unlike prior benchmarks that focus primarily on single-function annotation, DafnyCOMP targets programs composed of 2-5 functions arranged in acyclic call graphs, requiring specifications that establish correctness across component boundaries. DafnyCOMP contains 400 automatically synthesized programs: 300 chain-structured instances and 100 non-chain DAG instances generated from 10 topology templates. We evaluate frontier LLMs from major providers under a unified prompting and verification protocol. While these models achieve high syntactic well-formedness (>99%) and moderate end-to-end verification (>58%) on prior single-function Dafny verification benchmarks, they obtain near-zero end-to-end verification on DafnyCOMP. On the chain split, even the strongest evaluated model reaches only 2% verification at Pass@8, with most models below 1%; the difficulty persists under broader topologies and stronger test-time scaling. Our analysis identifies three recurring failure modes that hinder cross-functional reasoning: specification fragility, implementation--proof misalignment, and reasoning instability. DafnyCOMP provides a diagnostic benchmark for tracking progress in verifiable code generation, highlighting that bridging local correctness to compositional verification remains a key open challenge.