GRACE: A Language Model Framework for Explainable Inverse Reinforcement Learning
{kind=link}
Abstract
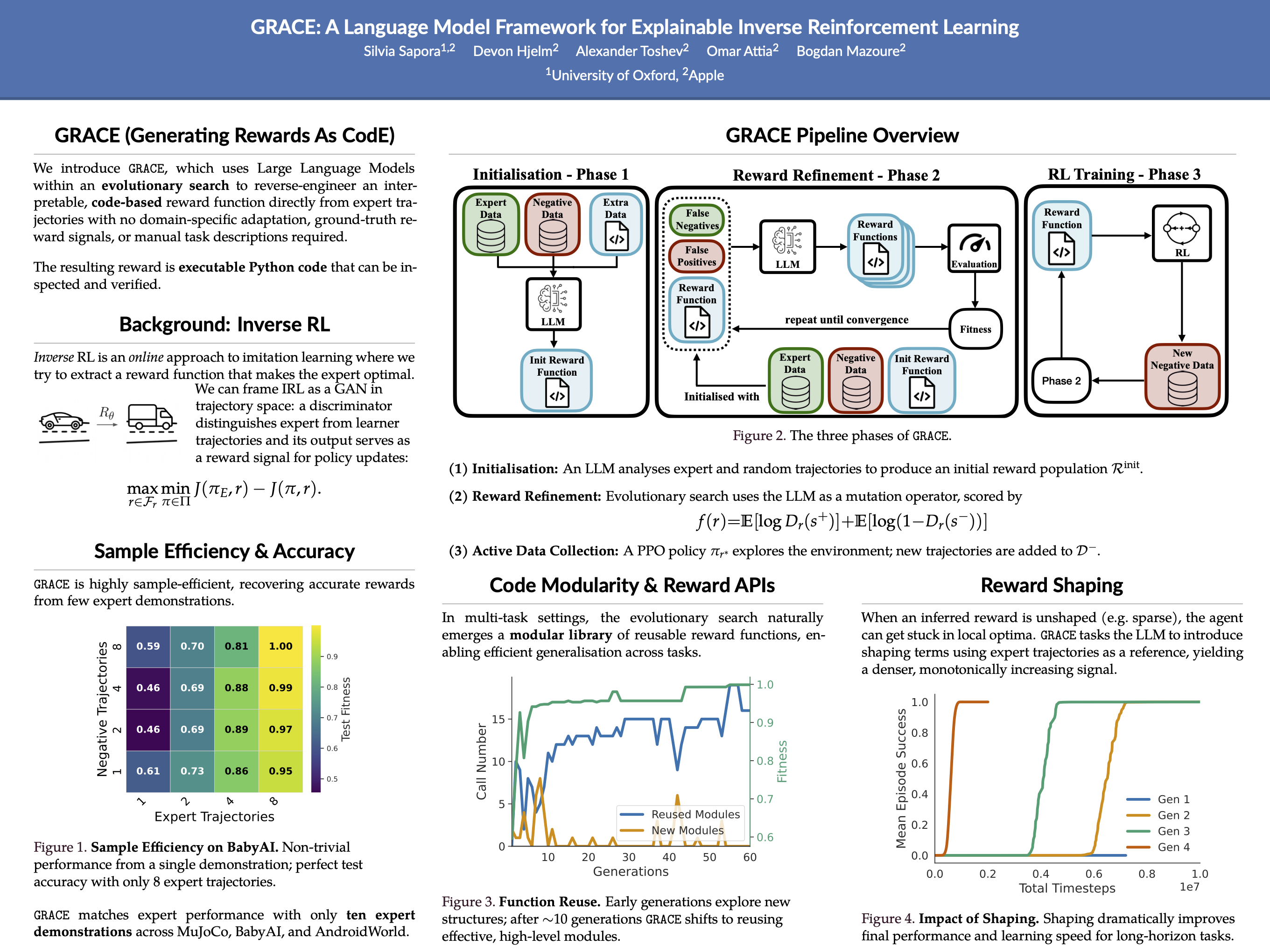
Inverse Reinforcement Learning aims to recover reward models from expert demonstrations, but traditional methods yield black-box models that are difficult to interpret and debug. In this work, we introduce GRACE (Generating Rewards As CodE), a method for using Large Language Models within an evolutionary search to reverse-engineer an interpretable, code-based reward function directly from expert trajectories. The resulting reward function is executable code that can be inspected and verified. We empirically validate GRACE on the MuJoCo, BabyAI and AndroidWorld benchmarks, where it efficiently learns highly accurate rewards, even in complex, multi-task settings. Further, we demonstrate that the resulting reward leads to strong policies, compared to both competitive Imitation Learning and online RL approaches with ground-truth rewards. Finally, we show that GRACE is able to build complex reward APIs in multi-task setups.