HUME: Measuring the Human-Model Performance Gap in Text Embedding Tasks
{kind=link}
Abstract
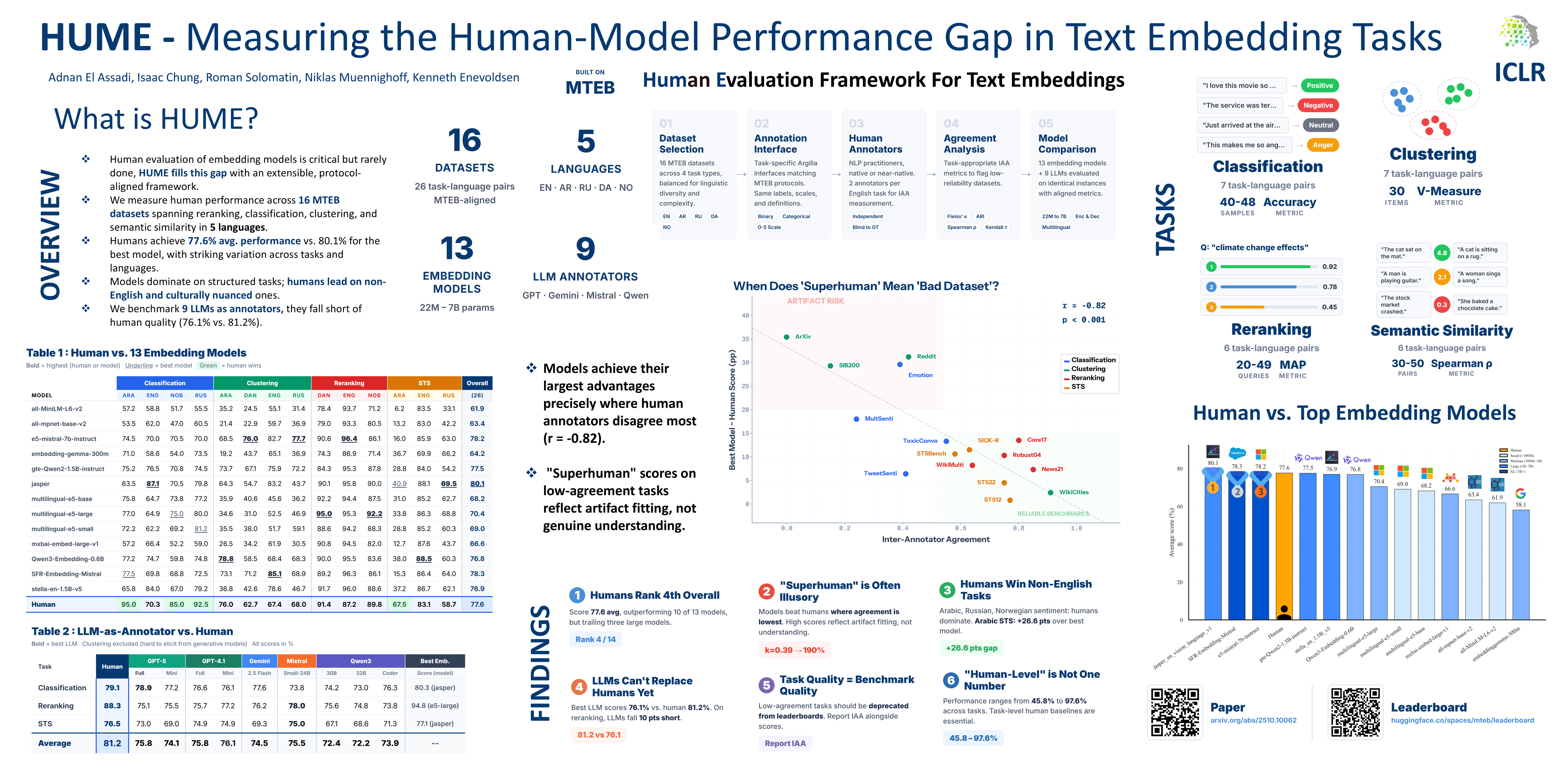
Comparing human and model performance offers a valuable perspective for understanding the strengths and limitations of embedding models, highlighting where they succeed and where they fail to capture meaning and nuance. However, such comparisons are rarely made, as human performance on embedding tasks is difficult to measure. To fill this gap, we introduce HUME: Human Evaluation Framework for Text Embeddings. While frameworks like MTEB provide broad model evaluation, they lack reliable estimates of human performance, limiting the interpretability of model scores. We measure human performance across 16 MTEB datasets spanning reranking, classification, clustering, and semantic textual similarity across linguistically diverse high- and low-resource languages. Humans achieve an average performance of 77.6% compared to 80.1% for the best embedding model, though with substantial variation: models reach high performance on some datasets while struggling on notably low-resource languages. Our human annotations also reveal multiple dataset issues. We additionally benchmark nine LLMs as annotators on reranking, classification, and STS tasks, finding that they fall short of human performance (76.1% vs. 81.2%) despite offering scalability advantages. We provide human performance baselines, insights into task difficulty patterns, and an extensible evaluation framework that enables a more meaningful interpretation of results and informs the development of both models and benchmarks. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.