Learning What Matters Now: Dynamic Preference Inference under Contextual Shifts
{kind=link}
Abstract
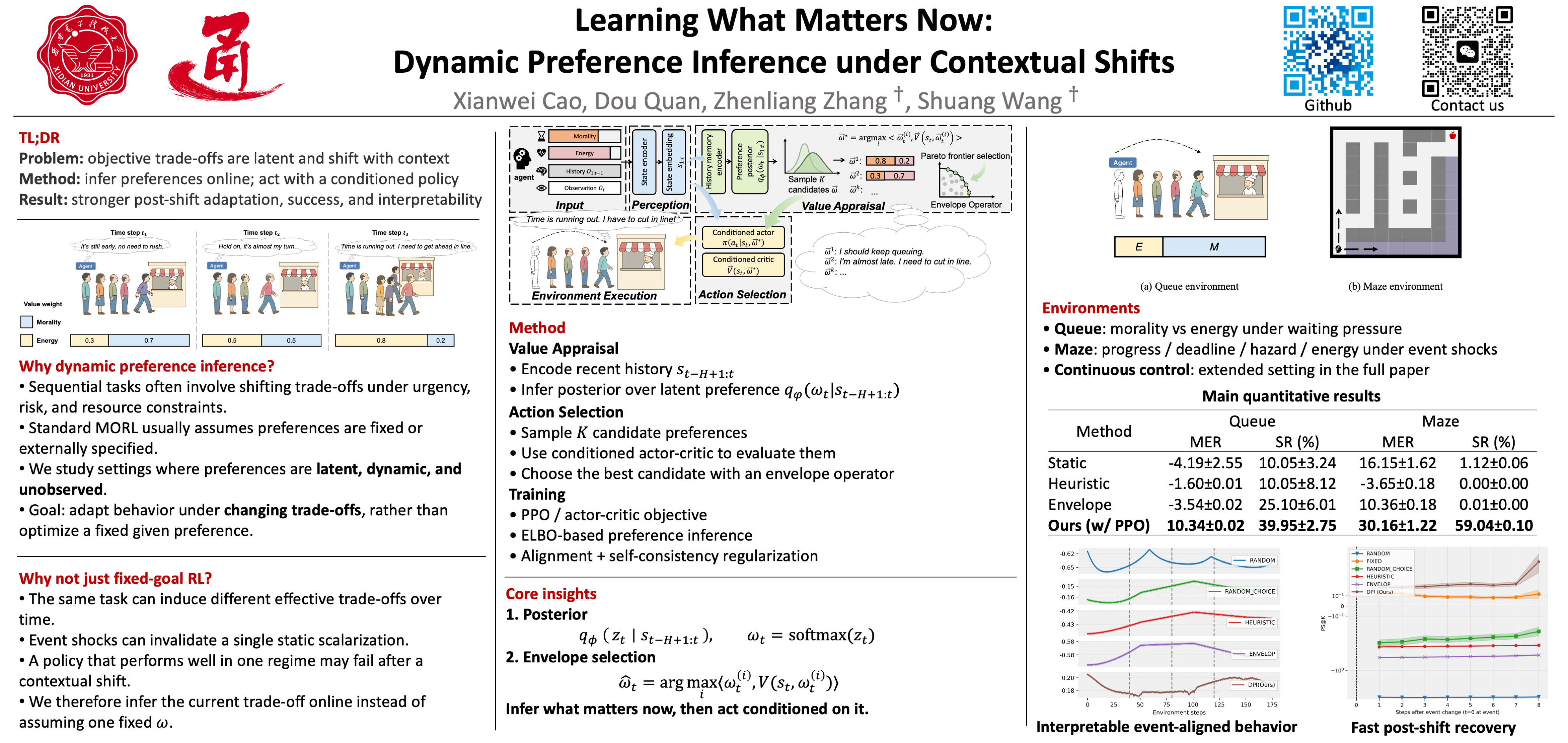
Humans often juggle multiple, sometimes conflicting objectives and shift their priorities as circumstances change, rather than following a fixed objective function. In contrast, most computational decision-making and multi-objective RL methods assume static preference weights or a known scalar reward. In this work, we study sequential decision-making problem when these preference weights are unobserved latent variables that drift with context. Specifically, we propose Dynamic Preference Inference (DPI), a cognitively inspired framework in which an agent maintains a probabilistic belief over preference weights, updates this belief from recent interaction, and conditions its policy on inferred preferences. We instantiate DPI as a variational preference inference module trained jointly with a preference-conditioned actor–critic, using vector-valued returns as evidence about latent trade-offs. In queueing, gridworld maze, and multi-objective continuous-control environments with event-driven changes in objectives, DPI adapts its inferred preferences to new regimes and achieves higher post-shift performance than fixed-weight and heuristic envelope baselines.