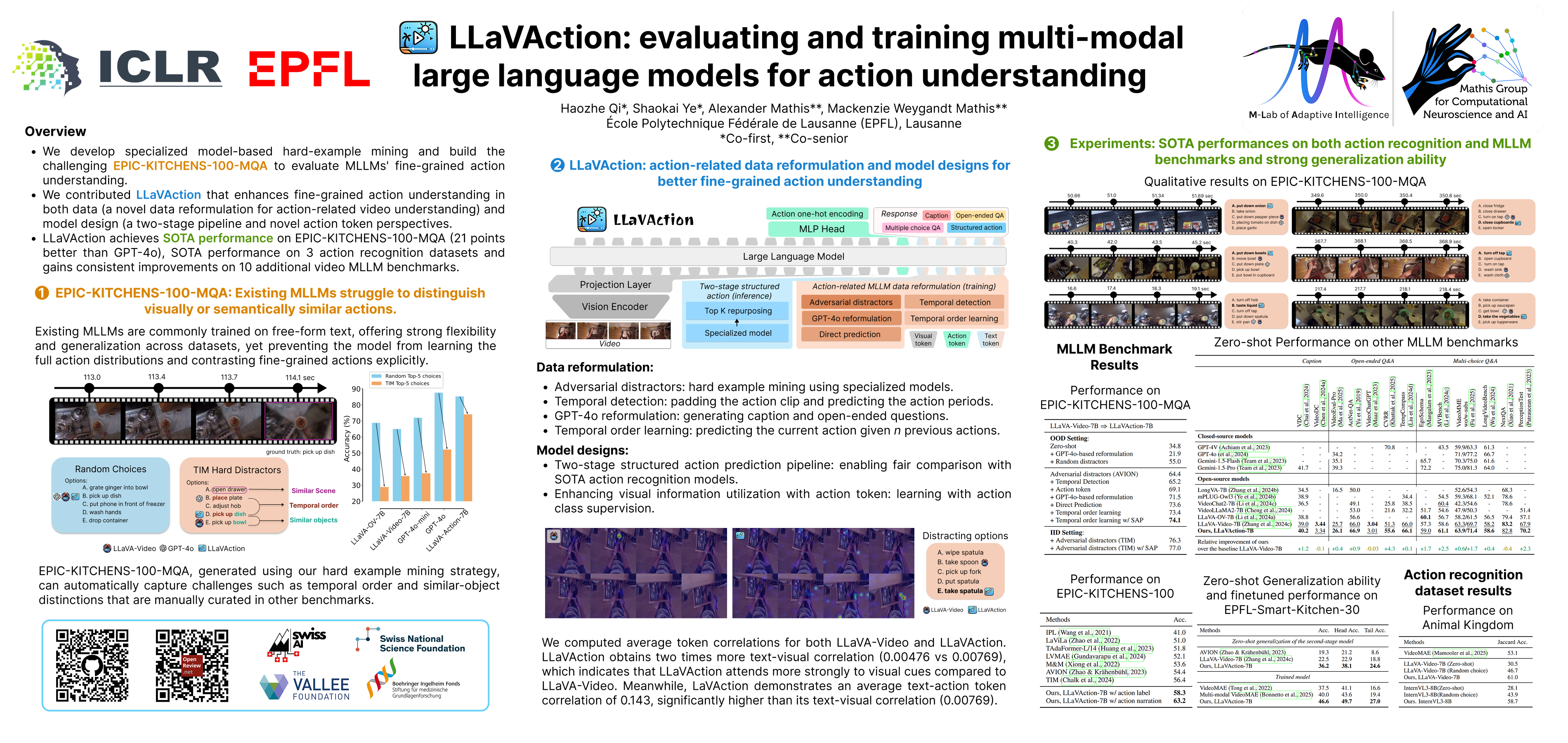
LLaVAction: evaluating and training multi-modal large language models for action understanding
{kind=link}
Abstract
Understanding human behavior requires measuring behavioral actions. Due to its complexity, behavior is best mapped onto a rich, semantic structure such as language. Emerging multimodal large language models (MLLMs) are promising candidates, but their fine-grained action understanding ability has not been fully examined. In this work, we reformulate EPIC-KITCHENS-100, one of the largest and most challenging egocentric action recognition datasets, into a MLLM benchmark (EPIC-KITCHENS-100-MQA). We demonstrate that when we sample difficult answers based on specialist models as distractors, leading MLLMs struggle to recognize the correct actions. How can we increase the performance of MLLMs? We curated a supervised finetuning dataset that includes `hard' action recognition, temporal detection, captioning, and free-form question answering to improve models' diverse action understanding capabilities. We introduce a new model called LLaVAction that adds an action token to boost models' attention on visual tokens and a two-stage pipeline to obtain structured actions. LLaVAction greatly improves the MLLMs' ability of action understanding, achieving strong improvements on both MLLM benchmarks (21 points in accuracy over GPT-4o on EPIC-KITCHENS-100-MQA) and established action recognition benchmarks, suggesting that our methods prepare MLLMs to be a promising path forward for complex action tasks. Code, data, the benchmark, and models are available at https://github.com/AdaptiveMotorControlLab/LLaVAction.