Latent Fourier Transform
{kind=link}
Abstract
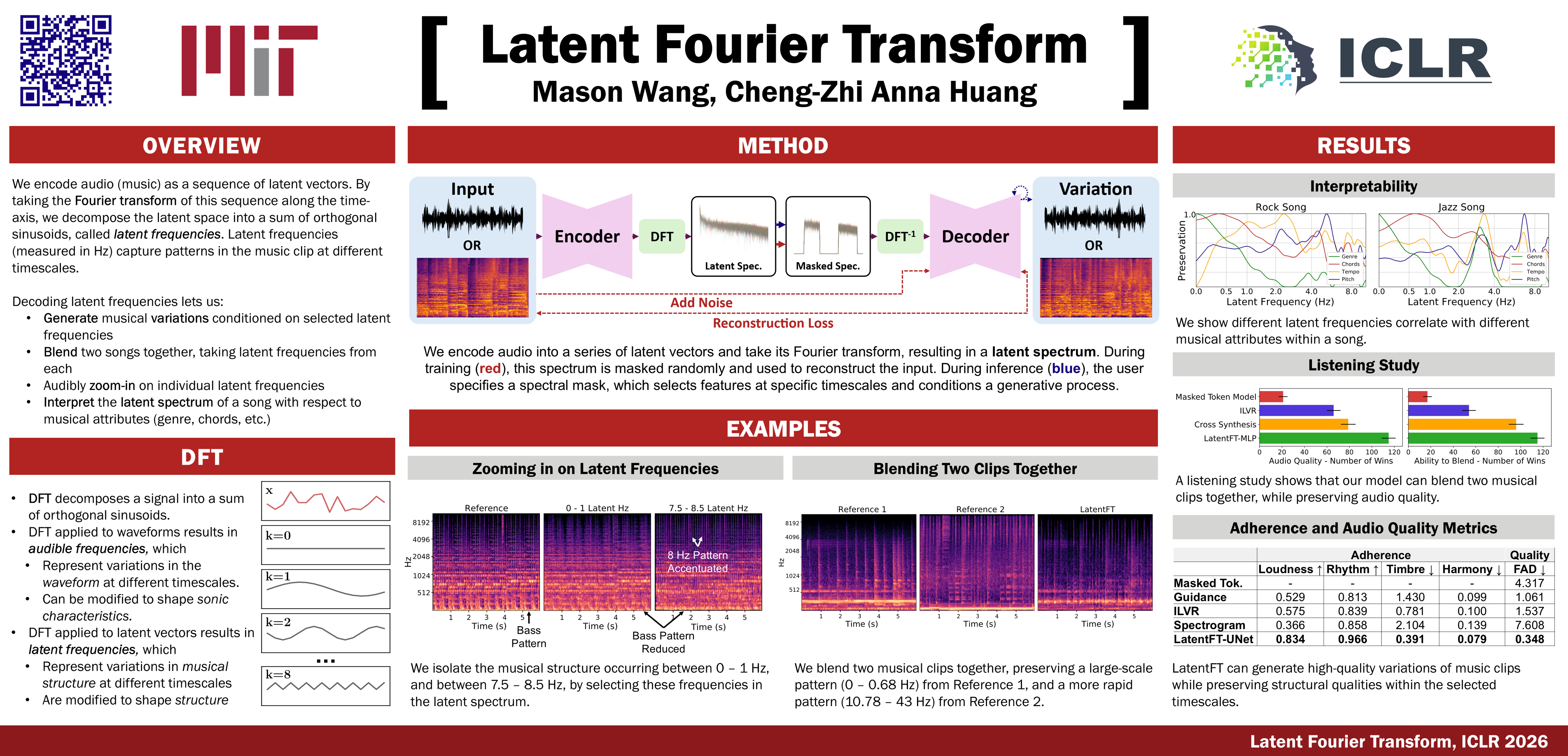
We introduce the Latent Fourier Transform (LatentFT), a framework that provides novel frequency-domain controls for generative music models. LatentFT combines a diffusion autoencoder with a latent-space Fourier transform to separate musical patterns by timescale. By masking latents in the frequency domain during training, our method yields representations that can be manipulated coherently at inference. This allows us to generate musical variations and blends from reference examples while preserving characteristics at desired timescales, which are specified as frequencies in the latent space. LatentFT parallels the role of the equalizer in music production: while traditional equalizers operates on audible frequencies to shape timbre, LatentFT operates on latent-space frequencies to shape musical structure. Experiments and listening tests show that LatentFT improves condition adherence and quality compared to baselines. We also present a technique for hearing frequencies in the latent space in isolation, and show different musical attributes reside in different regions of the latent spectrum. Our results show how frequency-domain control in latent space provides an intuitive, continuous frequency axis for conditioning and blending, advancing us toward more interpretable and interactive generative music models.