Swap-guided Preference Learning for Personalized Reinforcement Learning from Human Feedback
{kind=link}
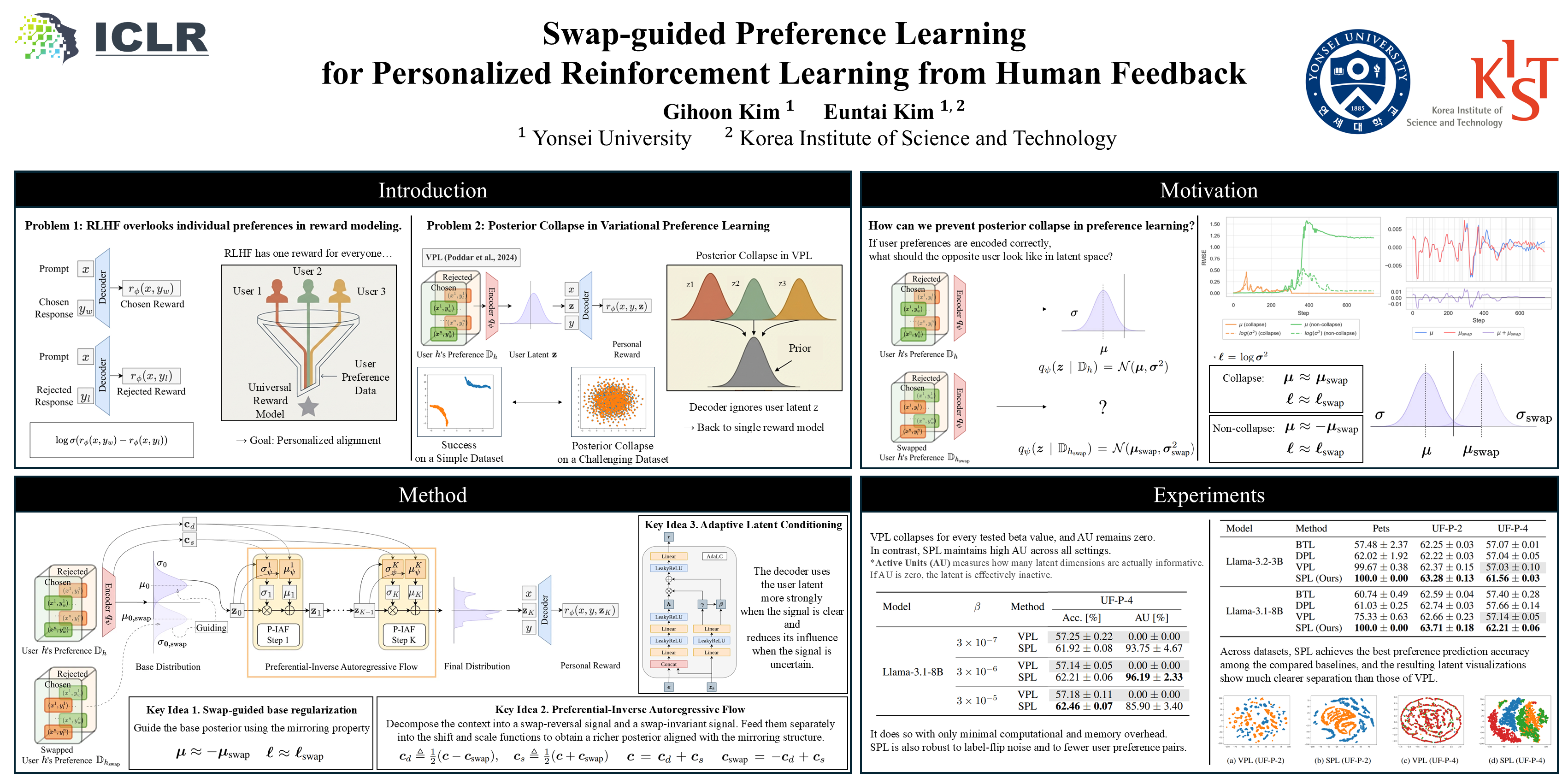
Abstract
Reinforcement Learning from Human Feedback (RLHF) is a widely used approach to align large-scale AI systems with human values. However, RLHF typically assumes a single, universal reward, which overlooks diverse preferences and limits personalization. Variational Preference Learning (VPL) seeks to address this by introducing user-specific latent variables. Despite its promise, we found that VPL suffers from posterior collapse. While this phenomenon is well known in VAEs, it has not previously been identified in preference learning frameworks. Under sparse preference data and with overly expressive decoders, VPL may cause latent variables to be ignored, reverting to a single-reward model. To overcome this limitation, we propose Swap-guided Preference Learning (SPL). The key idea is to construct fictitious swap annotators and use the mirroring property of their preferences to guide the encoder. SPL introduces three components: (1) swap-guided base regularization, (2) Preferential Inverse Autoregressive Flow (P-IAF), and (3) adaptive latent conditioning. Experiments show that SPL mitigates collapse, enriches user-specific latents, and improves preference prediction. Our code and data are available at https://github.com/cobang0111/SPL