Rethinking Radiology Report Generation: From Narrative Flow to Topic-Guided Findings
{kind=link}
Abstract
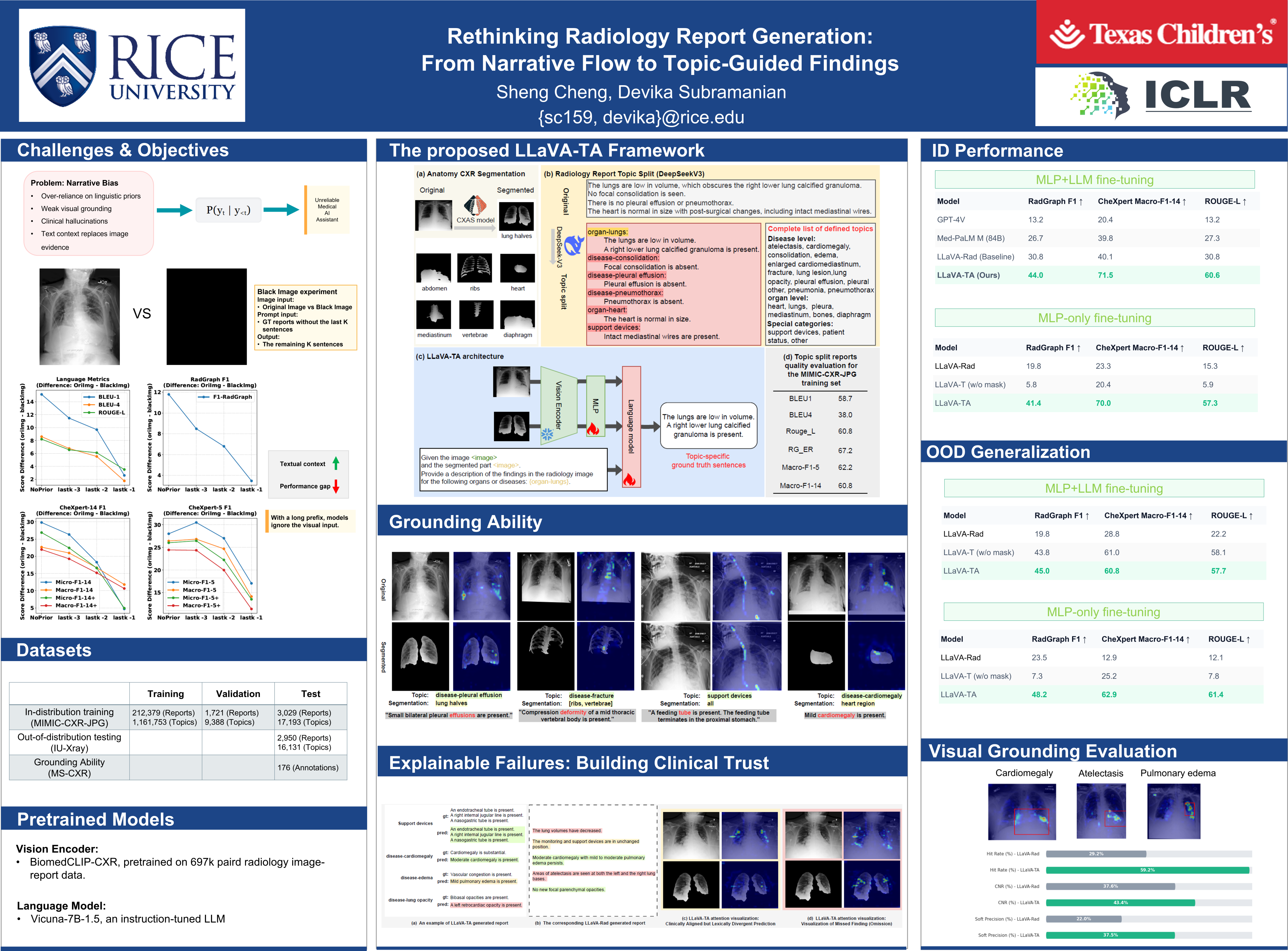
Vision-Language Models (VLMs) for radiology report generation are typically trained to mimic the narrative flow of human experts. However, we identify a potential limitation in this conventional paradigm. We hypothesize that optimizing for narrative coherence encourages models to rely on linguistic priors and inter-sentence correlations, which can weaken their grounding in direct visual evidence and lead to factual inaccuracies. To investigate this, we design a controlled experiment demonstrating that as textual context increases, a model's reliance on the input image systematically decays. We propose LLaVA-TA (Topic-guided and Anatomy-aware), a new fine-tuning framework that directly addresses this challenge by re-engineering the generation process. Instead of producing a linear narrative, LLaVA-TA decomposes the report into a set of independent, clinically-relevant topics. By training the model to generate a discrete finding for each topic conditioned on both the full image and its corresponding anatomical region, we reduce the model's reliance on narrative flow and enforce stricter visual grounding. Our experiments show that LLaVA-TA sets a new state of the art on the MIMIC-CXR dataset, significantly improving clinical accuracy on metrics like RadGraph F1 (from 29.4 to 44.0) and CheXpert F1-14 (from 39.5 to 71.5) over strong baselines. Our work demonstrates that dismantling a report's narrative structure to enforce independent, visually-grounded observations is a crucial and effective step toward building more accurate and reliable medical VLMs.