Equilibrium Language Models
{kind=link}
Abstract
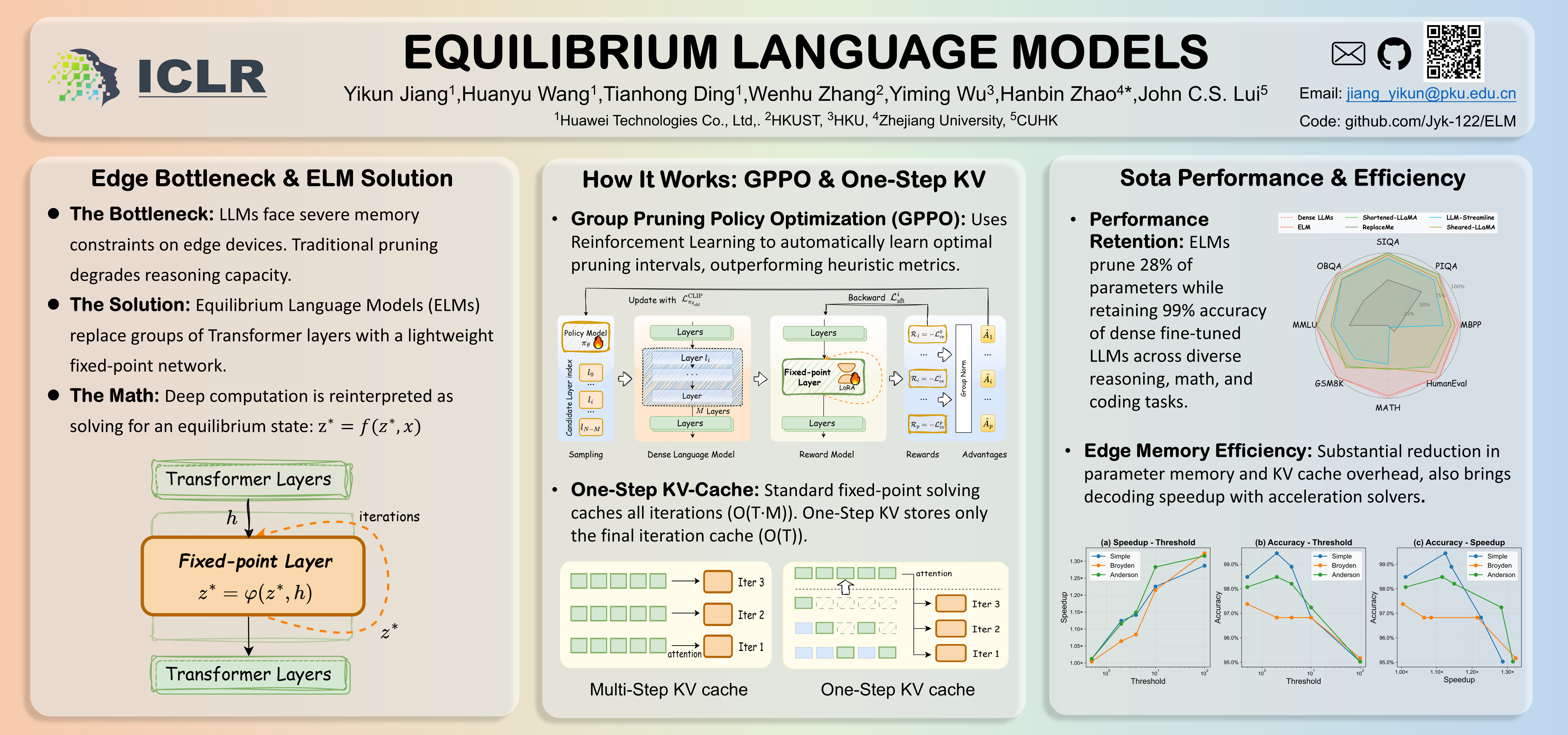
Large Language Models (LLMs) excel across diverse applications but remain impractical for edge deployment due to severe memory bottlenecks at the edge devices. We propose Equilibrium Language Models (ELMs), a novel compression framework that replaces groups of Transformer layers with a lightweight fixed-point network, reinterpreting deep computation as solving for an equilibrium state. To achieve ELMs, We introduce Group Pruning Policy Optimization, which automatically learns optimal pruning intervals. Moreover, we propose One-Step KV-Cache, which drastically reduces memory overhead by storing only the final iteration cache without compromising the accuracy, to enable effective deployment at the edge devices. Across different tasks such as common sense reasoning, mathematical problem solving, and code generation, ELMs prune 28\% of parameters while retaining 99\% of the accuracy of dense fine-tuned LLMs, establishing a new direction for memory-efficient edge deployment of large models.