LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
Jiyuan Fu ⋅ Kaixun Jiang ⋅ Lingyi Hong ⋅ Jinglun Li ⋅ HaiJing Guo ⋅ Dingkang Yang ⋅ Zhaoyu Chen ⋅ Wenqiang Zhang
{kind=link}
Abstract
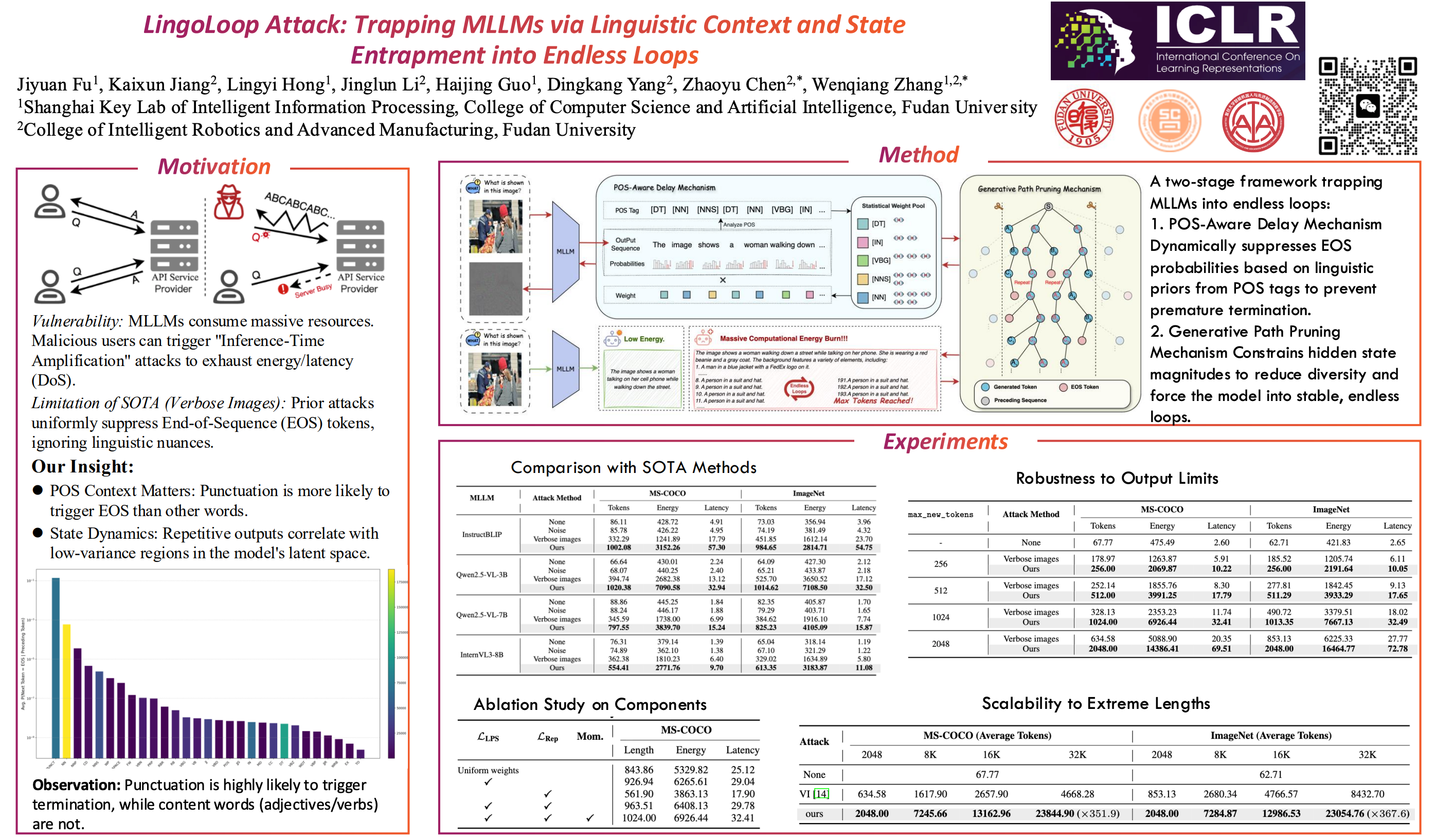
Multimodal Large Language Models (MLLMs) have shown great promise but require substantial computational resources during inference. Attackers can exploit this by inducing excessive output, leading to resource exhaustion and service degradation. Prior energy-latency attacks aim to increase generation time by broadly shifting the output token distribution away from the EOS token, but they neglect the influence of token-level Part-of-Speech (POS) characteristics on EOS and sentence-level structural patterns on output counts, limiting their efficacy. To address this, we propose \textbf{LingoLoop}, an attack designed to induce MLLMs to generate excessively verbose and repetitive sequences. First, we find that the POS tag of a token strongly affects the likelihood of generating an EOS token. Based on this insight, we propose a \textbf{POS-Aware Delay Mechanism} to postpone EOS token generation by adjusting attention weights guided by POS information. Second, we identify that constraining output diversity to induce repetitive loops is effective for sustained generation. We introduce a \textbf{Generative Path Pruning Mechanism} that limits the magnitude of hidden states, encouraging the model to produce persistent loops. Extensive experiments on models like Qwen2.5-VL-3B demonstrate LingoLoop's powerful ability to trap them in generative loops; it consistently drives them to their generation limits and, when those limits are relaxed, can induce outputs with up to \textbf{367$\times$} more tokens than clean inputs, triggering a commensurate surge in energy consumption. These findings expose significant MLLMs' vulnerabilities, posing challenges for their reliable deployment.
Video
Chat is not available.
Successful Page Load