Scaling Sequence-to-Sequence Generative Neural Rendering
{kind=link}
Abstract
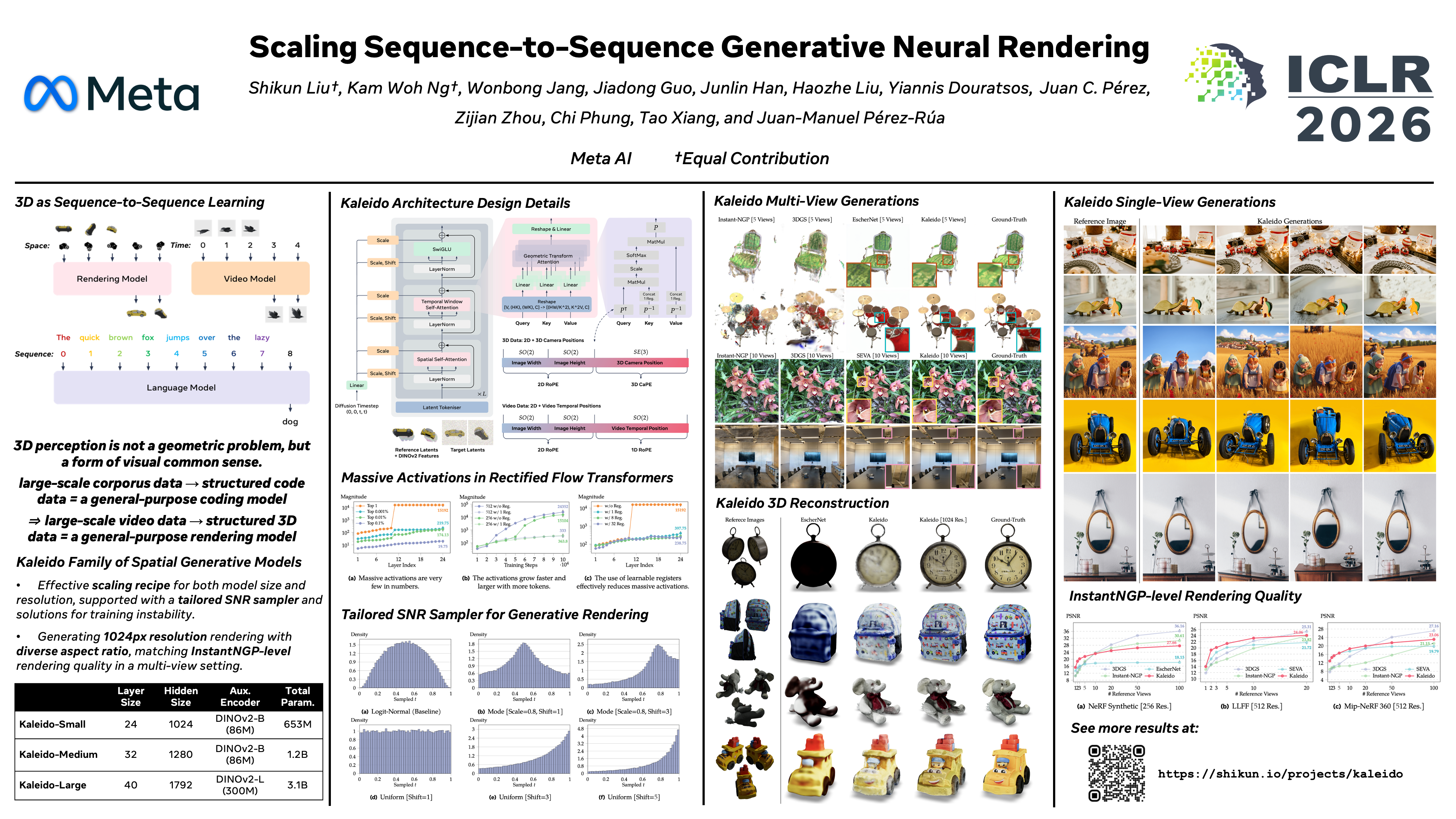
We present Kaleido, a family of generative models designed for photorealistic, unified object- and scene-level neural rendering. Kaleido is driven by the principle of treating 3D as a specialised sub-domain of video, which we formulate purely as a sequence-to-sequence image synthesis task. Through a systemic study of scaling sequence-to-sequence generative neural rendering, we introduce key architectural innovations that enable our model to: i) perform generative view synthesis without explicit 3D representations; ii) generate any number of 6-DoF target views conditioned on any number of reference views via a masked autoregressive framework; and iii) seamlessly unify 3D and video modelling within a single decoder-only rectified flow transformer. Within this unified framework, Kaleido leverages large-scale video data for pre-training, which significantly improves spatial consistency and reduces reliance on scarce, camera-labelled 3D datasets --- all without any architectural modifications. Kaleido sets a new state-of-the-art on a range of view synthesis benchmarks. Its zero-shot performance substantially outperforms other generative methods in few-view settings, and, for the first time, matches the quality of per-scene optimisation methods in many-view settings. For supplementary materials, including Kaleido's generated renderings and videos, please refer to our website: https://shikun.io/projects/kaleido.