Astraea: A Token-wise Acceleration Framework for Video Diffusion Transformers
{kind=link}
Abstract
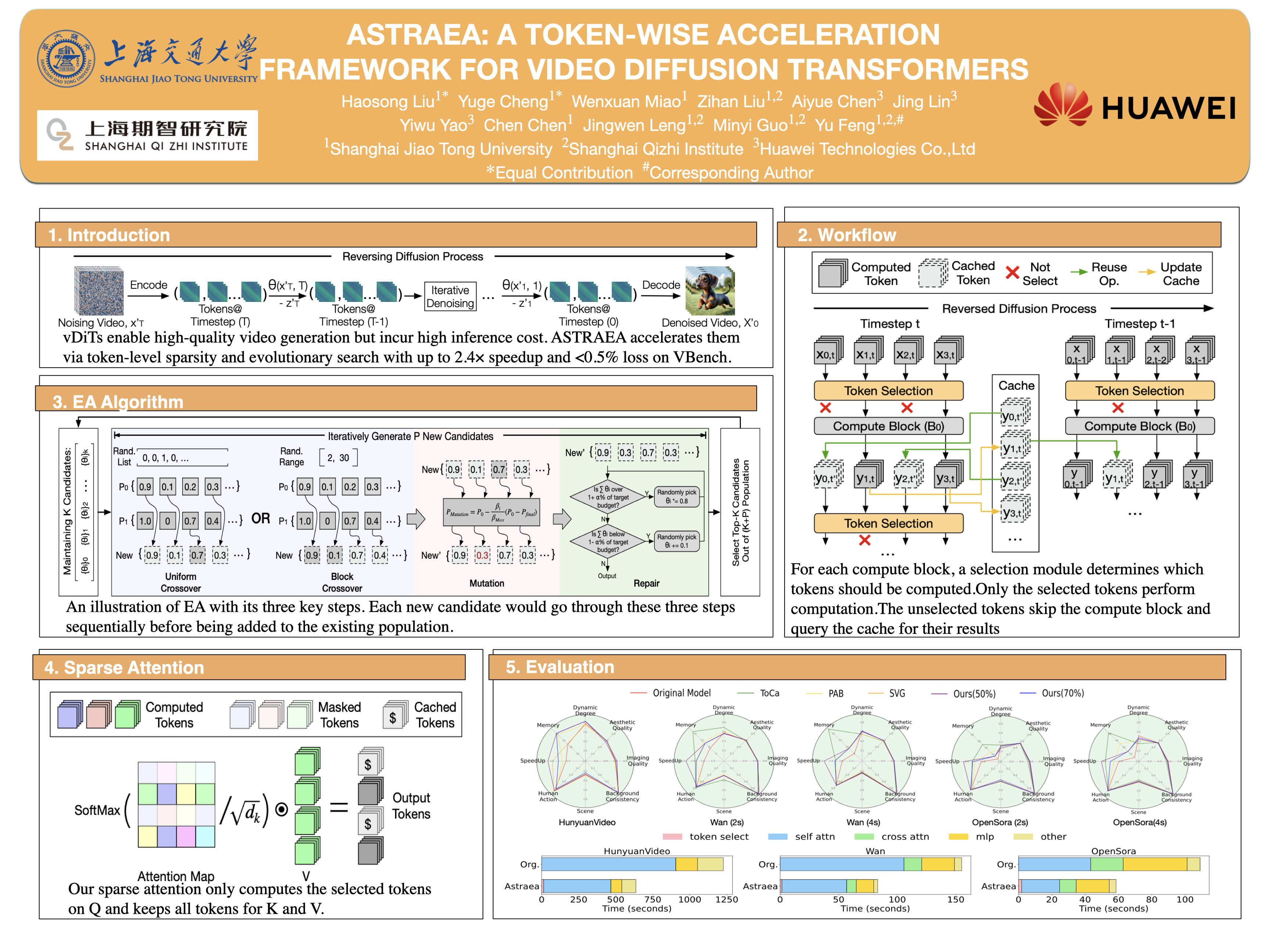
Video diffusion transformers (vDiTs) have made tremendous progress in text-to-video generation, but their high computational demands pose a major challenge for practical deployment. While existing studies propose acceleration methods to reduce workload at various granularities, they often rely on heuristics, limiting their applicability. We introduce Astraea, a framework that searches for near-optimal configurations for vDiT-based video generation with a performance target. At its core, Astraea proposes a lightweight token selection mechanism and a memory-efficient, GPU-parallel sparse attention strategy, enabling linear reductions in execution time with minimal impact on generation quality. Meanwhile, to determine optimal token reduction for different timesteps, we further design a search framework that leverages a classic evolutionary algorithm to automatically determine the distribution of the token budget effectively. Together, Astraea achieves up to 2.4x inference speedup on a single GPU with great scalability (up to 13.2x speedup on 8 GPUs) while retaining better video quality compared to the state-of-the-art methods (<0.5% loss on the VBench score compared to the baseline vDiT models).