Measure Twice, Cut Once: A Semantic-Oriented Approach to Video Temporal Localization with Video LLMs
{kind=link}
Abstract
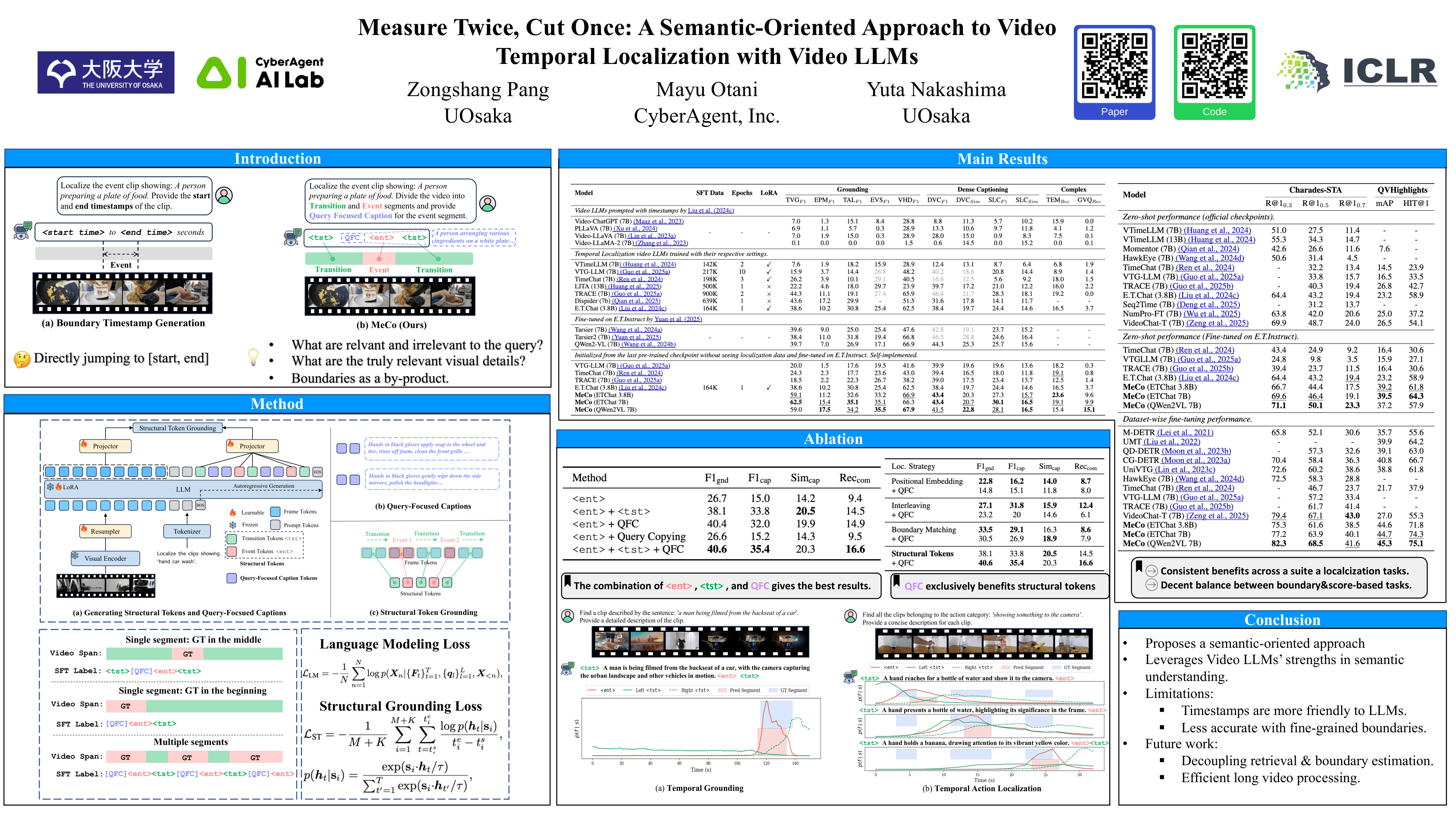
Temporally localizing user-queried events through natural language is a crucial capability for video models. Recent methods predominantly adapt video LLMs to generate event boundary timestamps for temporal localization tasks, which struggle to leverage LLMs' pre-trained semantic understanding capabilities due to the uninformative nature of timestamp outputs. In this work, we explore a timestamp-free, semantic-oriented framework that fine-tunes video LLMs using two generative learning tasks and one discriminative learning task. We first introduce a structural token generation task that enables the video LLM to recognize the temporal structure of input videos based on the input query. Through this task, the video LLM generates a sequence of special tokens, called structural tokens, which partition the video into consecutive segments and categorize them as either target events or background transitions. To enhance precise recognition of event segments, we further propose a query-focused captioning task that enables the video LLM to extract fine-grained event semantics that can be effectively utilized by the structural tokens. Finally, we introduce a structural token grounding module driven by contrastive learning to associate each structural token with its corresponding video segment, achieving holistic temporal segmentation of the input video and readily yielding the target event segments for localization. Extensive experiments across diverse temporal localization tasks demonstrate that our proposed framework, MeCo, consistently outperforms methods relying on boundary timestamp generation, highlighting the potential of a semantic-driven approach for temporal localization with video LLMs.