MedVR: Annotation-Free Medical Visual Reasoning via Agentic Reinforcement Learning
{kind=link}
Abstract
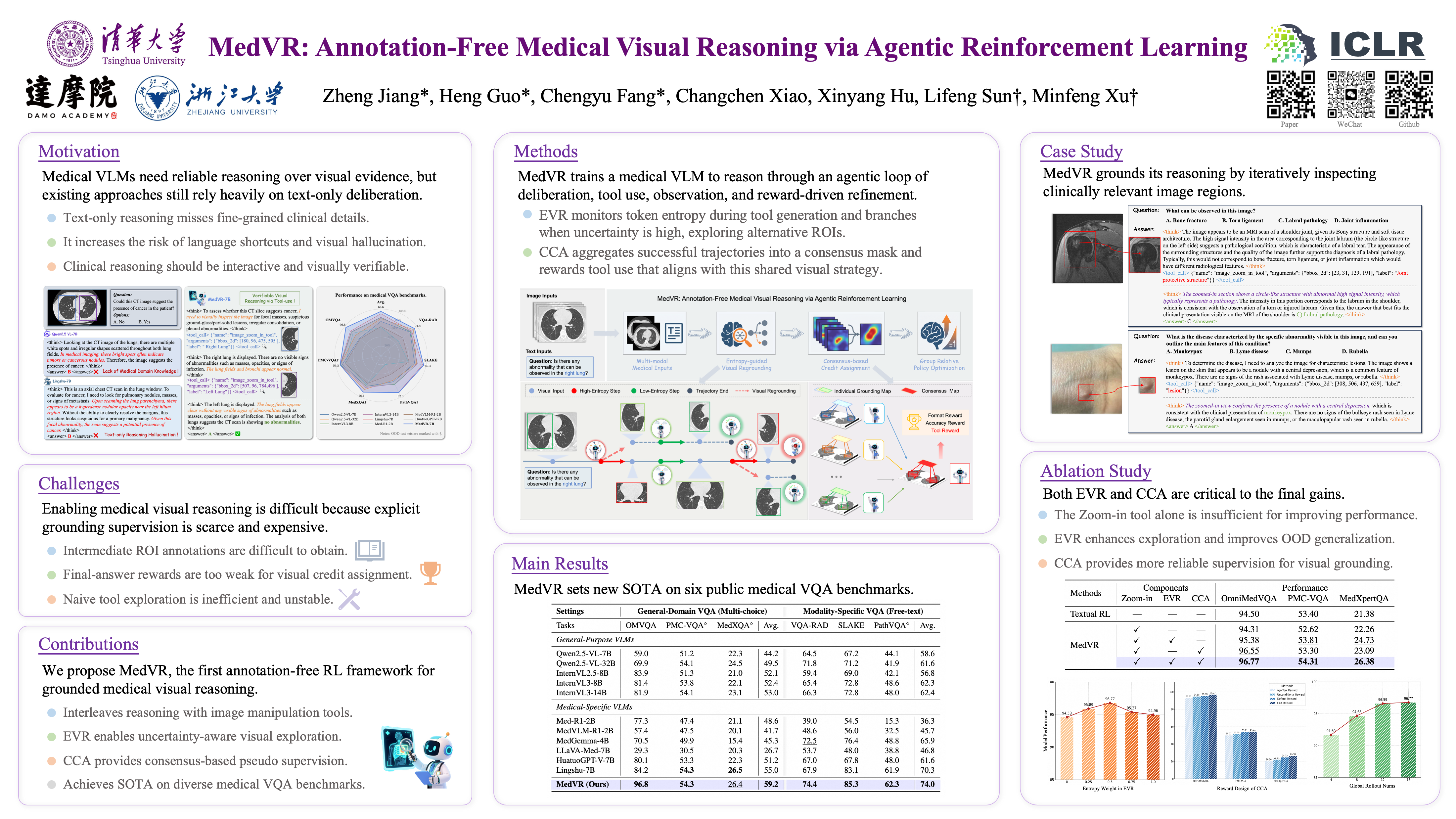
Medical Vision-Language Models (VLMs) hold immense promise for complex clinical tasks, but their reasoning capabilities are often constrained by text-only paradigms that fail to ground inferences in visual evidence. This limitation not only curtails performance on tasks requiring fine-grained visual analysis but also introduces risks of visual hallucination in safety-critical applications. Thus, we introduce MedVR, a novel reinforcement learning framework that enables annotation-free visual reasoning for medical VLMs. Its core innovation lies in two synergistic mechanisms: Entropy-guided Visual Regrounding (EVR) uses model uncertainty to direct exploration, while Consensus-based Credit Assignment (CCA) distills pseudo-supervision from rollout agreement. Without any human annotations for intermediate steps, MedVR achieves state-of-the-art performance on diverse public medical VQA benchmarks, significantly outperforming existing models. By learning to reason directly with visual evidence, MedVR promotes the robustness and transparency essential for accelerating the clinical deployment of medical AI.